搜索到
4
篇与
的结果
-
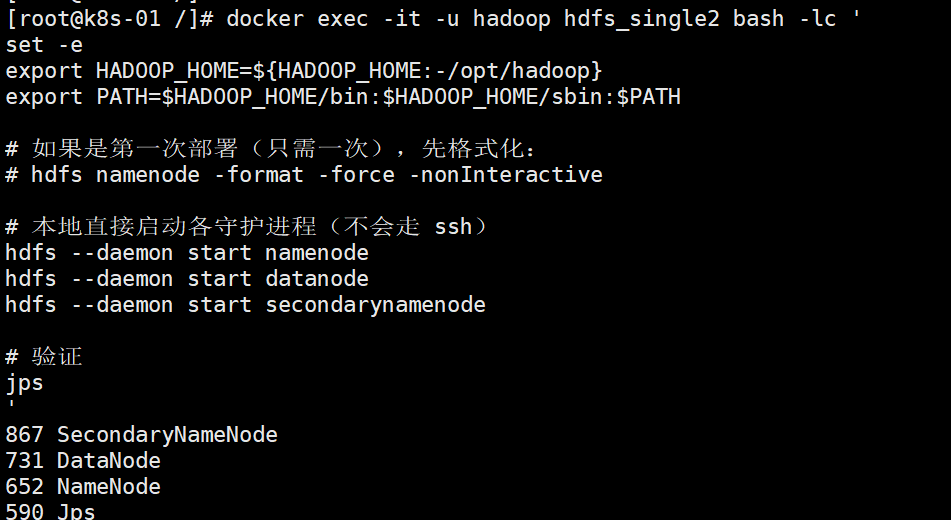
 4.0 HDFS 集群 一、准备工作HDFS 集群是建立在 Hadoop 集群之上的,由于 HDFS 是 Hadoop 最主要的守护进程,所以 HDFS 集群的配置过程是 Hadoop 集群配置过程的代表。 使用 Docker 可以更加方便地、高效地构建出一个集群环境。1.1 做hosts#三台机的hosts文件要提前做好 我这里因为是k8s节点已经提前做好了 [root@k8s-01 ~]# cat /etc/hosts 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.30.50 k8s-01 192.168.30.51 k8s-02 192.168.30.52 k8s-03 192.168.30.58 k8s-vip 192.168.30.50 goodrain.me1.2 做镜像# 在 k8s-01 上 docker save hadoop_proto:with-hdfs -o /root/hadoop_proto_with_hdfs.tar scp /root/hadoop_proto_with_hdfs.tar root@192.168.30.51:/root/ scp /root/hadoop_proto_with_hdfs.tar root@192.168.30.52:/root/ # 在 k8s-02、k8s-03 分别执行 docker load -i /root/hadoop_proto_with_hdfs.tar docker images | grep hadoop_proto1.3 在 k8s-02/03 为 DataNode 准备持久化目录(建议开始用宿主机目录做持久化,避免容器删掉后数据/元数据丢失) # k8s-02 mkdir -p /data/hdfs/datanode # k8s-03 mkdir -p /data/hdfs/datanode #如果容器里运行用户是 hadoop,建议给目录授权: #chown -R 1000:1000 /data/hdfs/datanode # 1000 常见是 hadoop 用户 UID,如不同再调整1.4 在 k8s-02/03 只启动 DataNode(不要再起 NameNode)方式 A:host 网络 + 覆盖 DN 配置 + 只拉起 DN # k8s-02 docker run -d \ --name hdfs-dn-02 \ --hostname hdfs-dn-02 \ --network host \ -v /data/hdfs/datanode:/usr/local/hadoop/dfs/data \ hadoop_proto:with-hdfs \ bash set -e # 1) 写入 DataNode 专用的 hdfs-site.xml(指明对外通告的主机IP) cat >/usr/local/hadoop/etc/hadoop/hdfs-site.xml << "EOF" <?xml version="1.0" encoding="UTF-8"?> <configuration> <property><name>dfs.datanode.data.dir</name><value>file:///usr/local/hadoop/dfs/data</value></property> <!-- 集群副本策略:沿用 3,也可以先设 2/1 过渡 --> <property><name>dfs.replication</name><value>3</value></property> <!-- DataNode 对外通告的地址=宿主机IP --> <property><name>dfs.datanode.use.datanode.hostname</name><value>true</value></property> <property><name>dfs.datanode.hostname</name><value>192.168.30.51</value></property> <!-- 监听地址 --> <property><name>dfs.datanode.address</name><value>0.0.0.0:9866</value></property> <property><name>dfs.datanode.http.address</name><value>0.0.0.0:9864</value></property> <property><name>dfs.datanode.ipc.address</name><value>0.0.0.0:9867</value></property> </configuration> EOF # 2) core-site.xml 保持指向 NameNode(192.168.30.50:9000) # 如果镜像里已经是这个值就不用动;保险起见再写一次: cat >/usr/local/hadoop/etc/hadoop/core-site.xml << "EOF" <?xml version="1.0" encoding="UTF-8"?> <configuration> <property><name>fs.defaultFS</name><value>hdfs://192.168.30.50:9000</value></property> <property><name>dfs.client.use.datanode.hostname</name><value>true</value></property> </configuration> EOF # 3) 只启动 DataNode /usr/local/hadoop/bin/hdfs --daemon start datanode # 4) 挂住容器(观察日志) tail -F /usr/local/hadoop/logs/*datanode*.log1.5 在 k8s-01 修改配置[hadoop@80b2f403b24e hadoop]$ cat ./core-site.xml <?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name>fs.defaultFS</name> <value>hdfs://192.168.30.50:9000</value> </property> <property> <name>dfs.client.use.datanode.hostname</name> <value>true</value> </property> </configuration> [hadoop@80b2f403b24e hadoop]$ cat ./hdfs-site.xml <?xml version="1.0" encoding="UTF-8"?> <configuration> <!-- NameNode / DataNode 本机目录 --> <property><name>dfs.namenode.name.dir</name><value>file:///usr/local/hadoop/dfs/name</value></property> <property><name>dfs.datanode.data.dir</name><value>file:///usr/local/hadoop/dfs/data</value></property> <property><name>dfs.replication</name><value>3</value></property> <!-- NN 监听与对外地址 --> <property><name>dfs.namenode.rpc-address</name><value>192.168.30.50:9000</value></property> <property><name>dfs.namenode.rpc-bind-host</name><value>0.0.0.0</value></property> <property><name>dfs.namenode.http-address</name><value>192.168.30.50:9870</value></property> <property><name>dfs.namenode.http-bind-host</name><value>0.0.0.0</value></property> <!-- 客户端/DN 使用主机名(或指定IP)模式 --> <property><name>dfs.client.use.datanode.hostname</name><value>true</value></property> <!-- 关键:放宽 NN 对 DN 注册时的 IP/主机名一致性校验 --> <property> <name>dfs.namenode.datanode.registration.ip-hostname-check</name> <value>false</value> </property> <!-- 本机若同时跑 DN,以下配置保留 --> <property><name>dfs.datanode.use.datanode.hostname</name><value>true</value></property> <property><name>dfs.datanode.hostname</name><value>192.168.30.50</value></property> <property><name>dfs.datanode.address</name><value>0.0.0.0:9866</value></property> <property><name>dfs.datanode.http.address</name><value>0.0.0.0:9864</value></property> <property><name>dfs.datanode.ipc.address</name><value>0.0.0.0:9867</value></property> </configuration> #如果是从我之前单节点执行过来的 可以执行下面的命令修改 也可以直接复制上面的命令修改 # 进入配置目录 cd /usr/local/hadoop/etc/hadoop # 备份 sudo cp -a hdfs-site.xml hdfs-site.xml.bak.$(date +%s) # 用 sudo tee 覆盖写入(注意:这里是覆盖而不是追加) sudo tee hdfs-site.xml >/dev/null <<'EOF' <?xml version="1.0" encoding="UTF-8"?> <configuration> <!-- NameNode / DataNode 本机目录 --> <property><name>dfs.namenode.name.dir</name><value>file:///usr/local/hadoop/dfs/name</value></property> <property><name>dfs.datanode.data.dir</name><value>file:///usr/local/hadoop/dfs/data</value></property> <property><name>dfs.replication</name><value>3</value></property> <!-- NN 监听与对外地址 --> <property><name>dfs.namenode.rpc-address</name><value>192.168.30.50:9000</value></property> <property><name>dfs.namenode.rpc-bind-host</name><value>0.0.0.0</value></property> <property><name>dfs.namenode.http-address</name><value>192.168.30.50:9870</value></property> <property><name>dfs.namenode.http-bind-host</name><value>0.0.0.0</value></property> <!-- 客户端/DN 使用主机名(或指定IP)模式 --> <property><name>dfs.client.use.datanode.hostname</name><value>true</value></property> <!-- 关键:放宽 NN 对 DN 注册时的 IP/主机名一致性校验 --> <property> <name>dfs.namenode.datanode.registration.ip-hostname-check</name> <value>false</value> </property> <!-- 本机若同时跑 DN,以下配置保留 --> <property><name>dfs.datanode.use.datanode.hostname</name><value>true</value></property> <property><name>dfs.datanode.hostname</name><value>192.168.30.50</value></property> <property><name>dfs.datanode.address</name><value>0.0.0.0:9866</value></property> <property><name>dfs.datanode.http.address</name><value>0.0.0.0:9864</value></property> <property><name>dfs.datanode.ipc.address</name><value>0.0.0.0:9867</value></property> </configuration> EOF1.6 重启# 重启 NameNode(以及本机 DataNode 让新配置生效) /usr/local/hadoop/bin/hdfs --daemon stop namenode sleep 2 /usr/local/hadoop/bin/hdfs --daemon start namenode /usr/local/hadoop/bin/hdfs --daemon stop datanode sleep 2 /usr/local/hadoop/bin/hdfs --daemon start datanode二、验证 2.1 在k8s-02/03 中确认 DN 监听正确端口(9864/9866/9867)且用宿主机 IP 对外通告# DN 是否在监听 9864/9866/9867 [root@hdfs-dn-02 tmp]# ss -lntp | egrep ':(9864|9866|9867)\b' || netstat -lntp | egrep ':(9864|9866|9867)\b' LISTEN 0 4096 0.0.0.0:9864 0.0.0.0:* users:(("java",pid=60,fd=389)) LISTEN 0 256 0.0.0.0:9867 0.0.0.0:* users:(("java",pid=60,fd=390)) LISTEN 0 256 0.0.0.0:9866 0.0.0.0:* users:(("java",pid=60,fd=333)) # 再从 NN 容器主动连过来测 DN 的 9867(IPC)和 9866(数据)是否可达 # 在 NN 容器执行下面两条,分别测 51/52: [root@hdfs-dn-02 tmp]# bash -lc 'echo > /dev/tcp/192.168.30.51/9867 && echo OK-51-9867 || echo FAIL' OK-51-9867 [root@hdfs-dn-02 tmp]# bash -lc 'echo > /dev/tcp/192.168.30.51/9866 && echo OK-51-9866 || echo FAIL' OK-51-9866 [root@hdfs-dn-02 tmp]# [root@hdfs-dn-02 tmp]# bash -lc 'echo > /dev/tcp/192.168.30.52/9867 && echo OK-52-9867 || echo FAIL' OK-52-9867 [root@hdfs-dn-02 tmp]# [root@hdfs-dn-02 tmp]# bash -lc 'echo > /dev/tcp/192.168.30.52/9866 && echo OK-52-9866 || echo FAIL' OK-52-9866 #如果这些端口不在监听,说明 DN 的 hdfs-site.xml 没生效或没用 host 网络。 #如果 FAIL,多半是 firewalld/iptables 拦了,放行 9864/9866/9867(DN)与 9000/9870(NN)。2.2 在k8s-01节点执行[hadoop@80b2f403b24e hadoop]$ hdfs dfsadmin -report Safe mode is ON Configured Capacity: 145030643712 (135.07 GB) Present Capacity: 92691496960 (86.33 GB) DFS Remaining: 92691451904 (86.33 GB) DFS Used: 45056 (44 KB) DFS Used%: 0.00% Replicated Blocks: Under replicated blocks: 0 Blocks with corrupt replicas: 0 Missing blocks: 0 Missing blocks (with replication factor 1): 0 Low redundancy blocks with highest priority to recover: 0 Pending deletion blocks: 0 Erasure Coded Block Groups: Low redundancy block groups: 0 Block groups with corrupt internal blocks: 0 Missing block groups: 0 Low redundancy blocks with highest priority to recover: 0 Pending deletion blocks: 0 ------------------------------------------------- Live datanodes (3): Name: 172.17.0.1:9866 (_gateway) Hostname: 192.168.30.50 Decommission Status : Normal Configured Capacity: 48343547904 (45.02 GB) DFS Used: 28672 (28 KB) Non DFS Used: 25802944512 (24.03 GB) DFS Remaining: 22540574720 (20.99 GB) DFS Used%: 0.00% DFS Remaining%: 46.63% Configured Cache Capacity: 0 (0 B) Cache Used: 0 (0 B) Cache Remaining: 0 (0 B) Cache Used%: 100.00% Cache Remaining%: 0.00% Xceivers: 0 Last contact: Sun Sep 21 14:40:41 UTC 2025 Last Block Report: Sun Sep 21 14:40:29 UTC 2025 Num of Blocks: 2 Name: 192.168.30.51:9866 (192.168.30.51) Hostname: 192.168.30.51 Decommission Status : Normal Configured Capacity: 48343547904 (45.02 GB) DFS Used: 8192 (8 KB) Non DFS Used: 12121690112 (11.29 GB) DFS Remaining: 36221849600 (33.73 GB) DFS Used%: 0.00% DFS Remaining%: 74.93% Configured Cache Capacity: 0 (0 B) Cache Used: 0 (0 B) Cache Remaining: 0 (0 B) Cache Used%: 100.00% Cache Remaining%: 0.00% Xceivers: 0 Last contact: Sun Sep 21 14:40:43 UTC 2025 Last Block Report: Sun Sep 21 14:40:19 UTC 2025 Num of Blocks: 0 Name: 192.168.30.52:9866 (192.168.30.52) Hostname: 192.168.30.52 Decommission Status : Normal Configured Capacity: 48343547904 (45.02 GB) DFS Used: 8192 (8 KB) Non DFS Used: 14414512128 (13.42 GB) DFS Remaining: 33929027584 (31.60 GB) DFS Used%: 0.00% DFS Remaining%: 70.18% Configured Cache Capacity: 0 (0 B) Cache Used: 0 (0 B) Cache Remaining: 0 (0 B) Cache Used%: 100.00% Cache Remaining%: 0.00% Xceivers: 0 Last contact: Sun Sep 21 14:40:43 UTC 2025 Last Block Report: Sun Sep 21 14:40:19 UTC 2025 Num of Blocks: 0 [hadoop@80b2f403b24e hadoop]$ hdfs dfsadmin -printTopology Rack: /default-rack 192.168.30.52:9866 (192.168.30.52) In Service 172.17.0.1:9866 (_gateway) In Service 192.168.30.51:9866 (192.168.30.51) In Service 2.3 测试#在k8s-01中插入内容 echo xing | hdfs dfs -appendToFile - /tmp/hello.txt #在k8s-01/02/03查看内容 hdfs dfs -cat /tmp/hello.txt [hadoop@80b2f403b24e hadoop]$ echo xing | hdfs dfs -appendToFile - /tmp/hello.txt [hadoop@80b2f403b24e hadoop]$ hdfs dfs -cat /tmp/hello.txt hello xing [root@hdfs-dn-02 tmp]# hdfs dfs -cat /tmp/hello.txt hello xing [root@hdfs-dn-03 tmp]# hdfs dfs -cat /tmp/hello.txt hello xing 2.4 节点开机自动拉起# 让 Docker 自启(若未开启) sudo systemctl enable --now docker # 给容器加重启策略:除非手动 stop,否则跟随宿主机重启而自动拉起 sudo docker update --restart unless-stopped hdfs_single2 # k8s-01 上的 NN(+DN) 容器名 sudo docker update --restart unless-stopped hdfs-dn-02 # k8s-02 DN sudo docker update --restart unless-stopped hdfs-dn-03 # k8s-03 DN # 验证 docker inspect -f '{{.HostConfig.RestartPolicy.Name}}' hdfs_single2 docker inspect -f '{{.HostConfig.RestartPolicy.Name}}' hdfs-dn-02 docker inspect -f '{{.HostConfig.RestartPolicy.Name}}' hdfs-dn-03 # 都应显示:unless-stopped2.5 优化后续要优化k8s-01节点HDFS数据挂载到宿主机 避免数据丢失 配置docker-compose 管理
4.0 HDFS 集群 一、准备工作HDFS 集群是建立在 Hadoop 集群之上的,由于 HDFS 是 Hadoop 最主要的守护进程,所以 HDFS 集群的配置过程是 Hadoop 集群配置过程的代表。 使用 Docker 可以更加方便地、高效地构建出一个集群环境。1.1 做hosts#三台机的hosts文件要提前做好 我这里因为是k8s节点已经提前做好了 [root@k8s-01 ~]# cat /etc/hosts 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.30.50 k8s-01 192.168.30.51 k8s-02 192.168.30.52 k8s-03 192.168.30.58 k8s-vip 192.168.30.50 goodrain.me1.2 做镜像# 在 k8s-01 上 docker save hadoop_proto:with-hdfs -o /root/hadoop_proto_with_hdfs.tar scp /root/hadoop_proto_with_hdfs.tar root@192.168.30.51:/root/ scp /root/hadoop_proto_with_hdfs.tar root@192.168.30.52:/root/ # 在 k8s-02、k8s-03 分别执行 docker load -i /root/hadoop_proto_with_hdfs.tar docker images | grep hadoop_proto1.3 在 k8s-02/03 为 DataNode 准备持久化目录(建议开始用宿主机目录做持久化,避免容器删掉后数据/元数据丢失) # k8s-02 mkdir -p /data/hdfs/datanode # k8s-03 mkdir -p /data/hdfs/datanode #如果容器里运行用户是 hadoop,建议给目录授权: #chown -R 1000:1000 /data/hdfs/datanode # 1000 常见是 hadoop 用户 UID,如不同再调整1.4 在 k8s-02/03 只启动 DataNode(不要再起 NameNode)方式 A:host 网络 + 覆盖 DN 配置 + 只拉起 DN # k8s-02 docker run -d \ --name hdfs-dn-02 \ --hostname hdfs-dn-02 \ --network host \ -v /data/hdfs/datanode:/usr/local/hadoop/dfs/data \ hadoop_proto:with-hdfs \ bash set -e # 1) 写入 DataNode 专用的 hdfs-site.xml(指明对外通告的主机IP) cat >/usr/local/hadoop/etc/hadoop/hdfs-site.xml << "EOF" <?xml version="1.0" encoding="UTF-8"?> <configuration> <property><name>dfs.datanode.data.dir</name><value>file:///usr/local/hadoop/dfs/data</value></property> <!-- 集群副本策略:沿用 3,也可以先设 2/1 过渡 --> <property><name>dfs.replication</name><value>3</value></property> <!-- DataNode 对外通告的地址=宿主机IP --> <property><name>dfs.datanode.use.datanode.hostname</name><value>true</value></property> <property><name>dfs.datanode.hostname</name><value>192.168.30.51</value></property> <!-- 监听地址 --> <property><name>dfs.datanode.address</name><value>0.0.0.0:9866</value></property> <property><name>dfs.datanode.http.address</name><value>0.0.0.0:9864</value></property> <property><name>dfs.datanode.ipc.address</name><value>0.0.0.0:9867</value></property> </configuration> EOF # 2) core-site.xml 保持指向 NameNode(192.168.30.50:9000) # 如果镜像里已经是这个值就不用动;保险起见再写一次: cat >/usr/local/hadoop/etc/hadoop/core-site.xml << "EOF" <?xml version="1.0" encoding="UTF-8"?> <configuration> <property><name>fs.defaultFS</name><value>hdfs://192.168.30.50:9000</value></property> <property><name>dfs.client.use.datanode.hostname</name><value>true</value></property> </configuration> EOF # 3) 只启动 DataNode /usr/local/hadoop/bin/hdfs --daemon start datanode # 4) 挂住容器(观察日志) tail -F /usr/local/hadoop/logs/*datanode*.log1.5 在 k8s-01 修改配置[hadoop@80b2f403b24e hadoop]$ cat ./core-site.xml <?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name>fs.defaultFS</name> <value>hdfs://192.168.30.50:9000</value> </property> <property> <name>dfs.client.use.datanode.hostname</name> <value>true</value> </property> </configuration> [hadoop@80b2f403b24e hadoop]$ cat ./hdfs-site.xml <?xml version="1.0" encoding="UTF-8"?> <configuration> <!-- NameNode / DataNode 本机目录 --> <property><name>dfs.namenode.name.dir</name><value>file:///usr/local/hadoop/dfs/name</value></property> <property><name>dfs.datanode.data.dir</name><value>file:///usr/local/hadoop/dfs/data</value></property> <property><name>dfs.replication</name><value>3</value></property> <!-- NN 监听与对外地址 --> <property><name>dfs.namenode.rpc-address</name><value>192.168.30.50:9000</value></property> <property><name>dfs.namenode.rpc-bind-host</name><value>0.0.0.0</value></property> <property><name>dfs.namenode.http-address</name><value>192.168.30.50:9870</value></property> <property><name>dfs.namenode.http-bind-host</name><value>0.0.0.0</value></property> <!-- 客户端/DN 使用主机名(或指定IP)模式 --> <property><name>dfs.client.use.datanode.hostname</name><value>true</value></property> <!-- 关键:放宽 NN 对 DN 注册时的 IP/主机名一致性校验 --> <property> <name>dfs.namenode.datanode.registration.ip-hostname-check</name> <value>false</value> </property> <!-- 本机若同时跑 DN,以下配置保留 --> <property><name>dfs.datanode.use.datanode.hostname</name><value>true</value></property> <property><name>dfs.datanode.hostname</name><value>192.168.30.50</value></property> <property><name>dfs.datanode.address</name><value>0.0.0.0:9866</value></property> <property><name>dfs.datanode.http.address</name><value>0.0.0.0:9864</value></property> <property><name>dfs.datanode.ipc.address</name><value>0.0.0.0:9867</value></property> </configuration> #如果是从我之前单节点执行过来的 可以执行下面的命令修改 也可以直接复制上面的命令修改 # 进入配置目录 cd /usr/local/hadoop/etc/hadoop # 备份 sudo cp -a hdfs-site.xml hdfs-site.xml.bak.$(date +%s) # 用 sudo tee 覆盖写入(注意:这里是覆盖而不是追加) sudo tee hdfs-site.xml >/dev/null <<'EOF' <?xml version="1.0" encoding="UTF-8"?> <configuration> <!-- NameNode / DataNode 本机目录 --> <property><name>dfs.namenode.name.dir</name><value>file:///usr/local/hadoop/dfs/name</value></property> <property><name>dfs.datanode.data.dir</name><value>file:///usr/local/hadoop/dfs/data</value></property> <property><name>dfs.replication</name><value>3</value></property> <!-- NN 监听与对外地址 --> <property><name>dfs.namenode.rpc-address</name><value>192.168.30.50:9000</value></property> <property><name>dfs.namenode.rpc-bind-host</name><value>0.0.0.0</value></property> <property><name>dfs.namenode.http-address</name><value>192.168.30.50:9870</value></property> <property><name>dfs.namenode.http-bind-host</name><value>0.0.0.0</value></property> <!-- 客户端/DN 使用主机名(或指定IP)模式 --> <property><name>dfs.client.use.datanode.hostname</name><value>true</value></property> <!-- 关键:放宽 NN 对 DN 注册时的 IP/主机名一致性校验 --> <property> <name>dfs.namenode.datanode.registration.ip-hostname-check</name> <value>false</value> </property> <!-- 本机若同时跑 DN,以下配置保留 --> <property><name>dfs.datanode.use.datanode.hostname</name><value>true</value></property> <property><name>dfs.datanode.hostname</name><value>192.168.30.50</value></property> <property><name>dfs.datanode.address</name><value>0.0.0.0:9866</value></property> <property><name>dfs.datanode.http.address</name><value>0.0.0.0:9864</value></property> <property><name>dfs.datanode.ipc.address</name><value>0.0.0.0:9867</value></property> </configuration> EOF1.6 重启# 重启 NameNode(以及本机 DataNode 让新配置生效) /usr/local/hadoop/bin/hdfs --daemon stop namenode sleep 2 /usr/local/hadoop/bin/hdfs --daemon start namenode /usr/local/hadoop/bin/hdfs --daemon stop datanode sleep 2 /usr/local/hadoop/bin/hdfs --daemon start datanode二、验证 2.1 在k8s-02/03 中确认 DN 监听正确端口(9864/9866/9867)且用宿主机 IP 对外通告# DN 是否在监听 9864/9866/9867 [root@hdfs-dn-02 tmp]# ss -lntp | egrep ':(9864|9866|9867)\b' || netstat -lntp | egrep ':(9864|9866|9867)\b' LISTEN 0 4096 0.0.0.0:9864 0.0.0.0:* users:(("java",pid=60,fd=389)) LISTEN 0 256 0.0.0.0:9867 0.0.0.0:* users:(("java",pid=60,fd=390)) LISTEN 0 256 0.0.0.0:9866 0.0.0.0:* users:(("java",pid=60,fd=333)) # 再从 NN 容器主动连过来测 DN 的 9867(IPC)和 9866(数据)是否可达 # 在 NN 容器执行下面两条,分别测 51/52: [root@hdfs-dn-02 tmp]# bash -lc 'echo > /dev/tcp/192.168.30.51/9867 && echo OK-51-9867 || echo FAIL' OK-51-9867 [root@hdfs-dn-02 tmp]# bash -lc 'echo > /dev/tcp/192.168.30.51/9866 && echo OK-51-9866 || echo FAIL' OK-51-9866 [root@hdfs-dn-02 tmp]# [root@hdfs-dn-02 tmp]# bash -lc 'echo > /dev/tcp/192.168.30.52/9867 && echo OK-52-9867 || echo FAIL' OK-52-9867 [root@hdfs-dn-02 tmp]# [root@hdfs-dn-02 tmp]# bash -lc 'echo > /dev/tcp/192.168.30.52/9866 && echo OK-52-9866 || echo FAIL' OK-52-9866 #如果这些端口不在监听,说明 DN 的 hdfs-site.xml 没生效或没用 host 网络。 #如果 FAIL,多半是 firewalld/iptables 拦了,放行 9864/9866/9867(DN)与 9000/9870(NN)。2.2 在k8s-01节点执行[hadoop@80b2f403b24e hadoop]$ hdfs dfsadmin -report Safe mode is ON Configured Capacity: 145030643712 (135.07 GB) Present Capacity: 92691496960 (86.33 GB) DFS Remaining: 92691451904 (86.33 GB) DFS Used: 45056 (44 KB) DFS Used%: 0.00% Replicated Blocks: Under replicated blocks: 0 Blocks with corrupt replicas: 0 Missing blocks: 0 Missing blocks (with replication factor 1): 0 Low redundancy blocks with highest priority to recover: 0 Pending deletion blocks: 0 Erasure Coded Block Groups: Low redundancy block groups: 0 Block groups with corrupt internal blocks: 0 Missing block groups: 0 Low redundancy blocks with highest priority to recover: 0 Pending deletion blocks: 0 ------------------------------------------------- Live datanodes (3): Name: 172.17.0.1:9866 (_gateway) Hostname: 192.168.30.50 Decommission Status : Normal Configured Capacity: 48343547904 (45.02 GB) DFS Used: 28672 (28 KB) Non DFS Used: 25802944512 (24.03 GB) DFS Remaining: 22540574720 (20.99 GB) DFS Used%: 0.00% DFS Remaining%: 46.63% Configured Cache Capacity: 0 (0 B) Cache Used: 0 (0 B) Cache Remaining: 0 (0 B) Cache Used%: 100.00% Cache Remaining%: 0.00% Xceivers: 0 Last contact: Sun Sep 21 14:40:41 UTC 2025 Last Block Report: Sun Sep 21 14:40:29 UTC 2025 Num of Blocks: 2 Name: 192.168.30.51:9866 (192.168.30.51) Hostname: 192.168.30.51 Decommission Status : Normal Configured Capacity: 48343547904 (45.02 GB) DFS Used: 8192 (8 KB) Non DFS Used: 12121690112 (11.29 GB) DFS Remaining: 36221849600 (33.73 GB) DFS Used%: 0.00% DFS Remaining%: 74.93% Configured Cache Capacity: 0 (0 B) Cache Used: 0 (0 B) Cache Remaining: 0 (0 B) Cache Used%: 100.00% Cache Remaining%: 0.00% Xceivers: 0 Last contact: Sun Sep 21 14:40:43 UTC 2025 Last Block Report: Sun Sep 21 14:40:19 UTC 2025 Num of Blocks: 0 Name: 192.168.30.52:9866 (192.168.30.52) Hostname: 192.168.30.52 Decommission Status : Normal Configured Capacity: 48343547904 (45.02 GB) DFS Used: 8192 (8 KB) Non DFS Used: 14414512128 (13.42 GB) DFS Remaining: 33929027584 (31.60 GB) DFS Used%: 0.00% DFS Remaining%: 70.18% Configured Cache Capacity: 0 (0 B) Cache Used: 0 (0 B) Cache Remaining: 0 (0 B) Cache Used%: 100.00% Cache Remaining%: 0.00% Xceivers: 0 Last contact: Sun Sep 21 14:40:43 UTC 2025 Last Block Report: Sun Sep 21 14:40:19 UTC 2025 Num of Blocks: 0 [hadoop@80b2f403b24e hadoop]$ hdfs dfsadmin -printTopology Rack: /default-rack 192.168.30.52:9866 (192.168.30.52) In Service 172.17.0.1:9866 (_gateway) In Service 192.168.30.51:9866 (192.168.30.51) In Service 2.3 测试#在k8s-01中插入内容 echo xing | hdfs dfs -appendToFile - /tmp/hello.txt #在k8s-01/02/03查看内容 hdfs dfs -cat /tmp/hello.txt [hadoop@80b2f403b24e hadoop]$ echo xing | hdfs dfs -appendToFile - /tmp/hello.txt [hadoop@80b2f403b24e hadoop]$ hdfs dfs -cat /tmp/hello.txt hello xing [root@hdfs-dn-02 tmp]# hdfs dfs -cat /tmp/hello.txt hello xing [root@hdfs-dn-03 tmp]# hdfs dfs -cat /tmp/hello.txt hello xing 2.4 节点开机自动拉起# 让 Docker 自启(若未开启) sudo systemctl enable --now docker # 给容器加重启策略:除非手动 stop,否则跟随宿主机重启而自动拉起 sudo docker update --restart unless-stopped hdfs_single2 # k8s-01 上的 NN(+DN) 容器名 sudo docker update --restart unless-stopped hdfs-dn-02 # k8s-02 DN sudo docker update --restart unless-stopped hdfs-dn-03 # k8s-03 DN # 验证 docker inspect -f '{{.HostConfig.RestartPolicy.Name}}' hdfs_single2 docker inspect -f '{{.HostConfig.RestartPolicy.Name}}' hdfs-dn-02 docker inspect -f '{{.HostConfig.RestartPolicy.Name}}' hdfs-dn-03 # 都应显示:unless-stopped2.5 优化后续要优化k8s-01节点HDFS数据挂载到宿主机 避免数据丢失 配置docker-compose 管理 -
3.0 HDFS 配置与使用 之前提到过的 Hadoop 三种模式:单机模式、伪集群模式和集群模式。 单机模式:Hadoop 仅作为库存在,可以在单计算机上执行 MapReduce 任务,仅用于开发者搭建学习和试验环境。 伪集群模式:此模式 Hadoop 将以守护进程的形式在单机运行,一般用于开发者搭建学习和试验环境。 集群模式:此模式是 Hadoop 的生产环境模式,也就是说这才是 Hadoop 真正使用的模式,用于提供生产级服务。一、HDFS 配置和启动HDFS 和数据库相似,是以守护进程的方式启动的。使用 HDFS 需要用 HDFS 客户端通过网络 (套接字) 连接到 HDFS 服务器实现文件系统的使用。 我们已经配置好了 Hadoop 的基础环境,容器名为 hadoop_single。如果你上次已经关闭了该容器或者关闭了计算机导致容器关闭,请启动并进入该容器。 进入该容器后,我们确认一下 Hadoop 是否存在: hadoop version #如果结果显示出 Hadoop 版本号则表示 Hadoop 存在。1.1 新建 hadoop 用户#新建用户,名为 hadoop: adduser hadoop #安装一个小工具用于修改用户密码和权限管理: yum install -y passwd sudo #设置 hadoop 用户密码 passwd hadoop #接下来两次输入密码,一定要记住! #修改 hadoop 安装目录所有人为 hadoop 用户: chown -R hadoop /usr/local/hadoop #然后用文本编辑器修改 /etc/sudoers 文件,在 root ALL=(ALL) ALL #之后添加一行 hadoop ALL=(ALL) ALL #然后退出容器。 #关闭并提交容器 hadoop_single 到镜像 hadoop_proto: docker stop hadoop_single docker commit hadoop_single hadoop_proto #创建新容器 hdfs_single : docker run -d --name=hdfs_single --privileged hadoop_proto /usr/sbin/init1.2 启动 HDFS#现在进入刚建立的容器: docker exec -it hdfs_single su hadoop #现在应该是 hadoop 用户: whoami #生成 SSH 密钥: ssh-keygen -t rsa #这里可以一直按回车直到生成结束。 #然后将生成的密钥添加到信任列表: ssh-copy-id hadoop@172.17.0.2 #查看容器 IP 地址: ip addr | grep 172 [hadoop@6eb1ec6bd5ce /]$ ip addr | grep 17 inet 172.17.0.2/16 brd 172.17.255.255 scope global eth0 #从而得知容器的 IP 地址是 172.17.0.2#在启动 HDFS 以前我们对其进行一些简单配置,Hadoop 配置文件全部储存在安装目录下的 etc/hadoop 子目录下,所以我们可以进入此目录: cd $HADOOP_HOME/etc/hadoop #这里我们修改两个文件:core-site.xml 和 hdfs-site.xml #在 core-site.xml 中,我们在 标签下添加属性: [hadoop@80b2f403b24e /]$ cd $HADOOP_HOME/etc/hadoop [hadoop@80b2f403b24e hadoop]$ pwd /usr/local/hadoop/etc/hadoop [hadoop@80b2f403b24e hadoop]$ cat ./core-site.xml <?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name>fs.defaultFS</name> <value>hdfs://192.168.30.50:9000</value> </property> </configuration> [hadoop@80b2f403b24e hadoop]$ [hadoop@80b2f403b24e hadoop]$ cat ./hdfs-site.xml <?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>dfs.namenode.name.dir</name> <value>file:///usr/local/hadoop/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:///usr/local/hadoop/dfs/data</value> </property> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.rpc-address</name> <value>192.168.30.50:9000</value> </property> <property> <name>dfs.namenode.rpc-bind-host</name> <value>0.0.0.0</value> </property> <property> <name>dfs.namenode.http-address</name> <value>192.168.30.50:9870</value> </property> <property> <name>dfs.namenode.http-bind-host</name> <value>0.0.0.0</value> </property> <property> <name>dfs.client.use.datanode.hostname</name> <value>true</value> </property> <property> <name>dfs.datanode.use.datanode.hostname</name> <value>true</value> </property> <property> <name>dfs.datanode.hostname</name> <value>192.168.30.50</value> </property> <property> <name>dfs.datanode.address</name> <value>0.0.0.0:9866</value> </property> <property> <name>dfs.datanode.http.address</name> <value>0.0.0.0:9864</value> </property> </configuration> # 建日志与数据目录 sudo mkdir -p /usr/local/hadoop/logs sudo mkdir -p /usr/local/hadoop/dfs/{name,data} # 把这些目录交给 hadoop 用户 sudo chown -R hadoop:hadoop /usr/local/hadoop/logs sudo chown -R hadoop:hadoop /usr/local/hadoop/dfsdocker stop hdfs_single [root@k8s-01 /]# docker run -d --name hdfs_single2 \ --privileged --cgroupns=host \ -v /sys/fs/cgroup:/sys/fs/cgroup:ro \ -p 9870:9870 \ -p 9000:9000 \ -p 9864:9864 \ -p 9866:9866 \ hadoop_proto:with-hdfs /usr/sbin/init 80b2f403b24eb1458cc2dbc852eeb50a46119f4f355f5a7ba0c204b32e288486 到此为止,HDFS 守护进程已经建立,由于 HDFS 本身具备 HTTP 面板,我们可以通过浏览器访问http://你的节点IP:9870/来查看 HDFS 面板以及详细信息:二、HDFS 使用 2.1 HDFS Shell#回到 hdfs_single 容器,以下命令将用于操作 HDFS: # 显示根目录 / 下的文件和子目录,绝对路径 hadoop fs -ls / # 新建文件夹,绝对路径 hadoop fs -mkdir /hello # 上传文件 hadoop fs -put hello.txt /hello/ # 下载文件 hadoop fs -get /hello/hello.txt # 输出文件内容 hadoop fs -cat /hello/hello.txt #HDFS 最基础的命令如上所述,除此之外还有许多其他传统文件系统所支持的操作。2.2 HDFS APIHDFS 已经被很多的后端平台所支持,目前官方在发行版中包含了 C/C++ 和 Java 的编程接口。此外,node.js 和 Python 语言的包管理器也支持导入 HDFS 的客户端。 以下是包管理器的依赖项列表: Maven: <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>3.1.4</version> </dependency> Gradle: providedCompile group: 'org.apache.hadoop', name: 'hadoop-hdfs-client', version: '3.1.4' NPM: npm i webhdfs pip: pip install hdfs#这里提供一个 Java 连接 HDFS 的例子(别忘了修改 IP 地址): package com.runoob; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.*; public class Application { public static void main(String[] args) { try { // 配置连接地址 Configuration conf = new Configuration(); conf.set("fs.defaultFS", "hdfs://172.17.0.2:9000"); FileSystem fs = FileSystem.get(conf); // 打开文件并读取输出 Path hello = new Path("/hello/hello.txt"); FSDataInputStream ins = fs.open(hello); int ch = ins.read(); while (ch != -1) { System.out.print((char)ch); ch = ins.read(); } System.out.println(); } catch (IOException ioe) { ioe.printStackTrace(); } } }
-
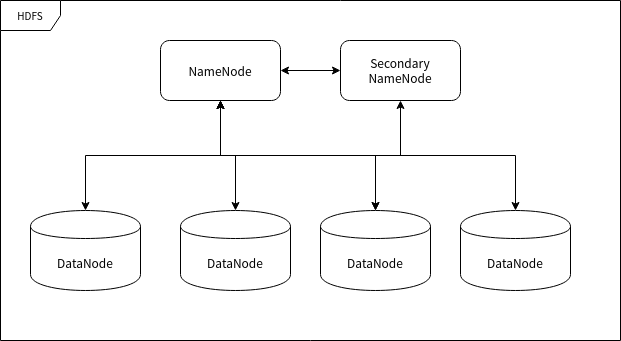
2.0 Hadoop 概念 一、Hadoop 整体设计Hadoop 框架是用于计算机集群大数据处理的框架,所以它必须是一个可以部署在多台计算机上的软件。部署了 Hadoop 软件的主机之间通过套接字 (网络) 进行通讯。 Hadoop 主要包含 HDFS 和 MapReduce 两大组件,HDFS 负责分布储存数据,MapReduce 负责对数据进行映射、规约处理,并汇总处理结果。 Hadoop 框架最根本的原理就是利用大量的计算机同时运算来加快大量数据的处理速度。例如,一个搜索引擎公司要从上万亿条没有进行规约的数据中筛选和归纳热门词汇就需要组织大量的计算机组成集群来处理这些信息。如果使用传统数据库来处理这些信息的话,那将会花费很长的时间和很大的处理空间来处理数据,这个量级对于任何单计算机来说都变得难以实现,主要难度在于组织大量的硬件并高速地集成为一个计算机,即使成功实现也会产生昂贵的维护成本。 Hadoop 可以在多达几千台廉价的量产计算机上运行,并把它们组织为一个计算机集群。 一个 Hadoop 集群可以高效地储存数据、分配处理任务,这样会有很多好处。首先可以降低计算机的建造和维护成本,其次,一旦任何一个计算机出现了硬件故障,不会对整个计算机系统造成致命的影响,因为面向应用层开发的集群框架本身就必须假定计算机会出故障。1.1 HDFSHadoop Distributed File System,Hadoop 分布式文件系统,简称 HDFS。 HDFS 用于在集群中储存文件,它所使用的核心思想是 Google 的 GFS 思想,可以存储很大的文件。 在服务器集群中,文件存储往往被要求高效而稳定,HDFS同时实现了这两个优点。 HDFS 高效的存储是通过计算机集群独立处理请求实现的。因为用户 (一半是后端程序) 在发出数据存储请求时,往往响应服务器正在处理其他请求,这是导致服务效率缓慢的主要原因。但如果响应服务器直接分配一个数据服务器给用户,然后用户直接与数据服务器交互,效率会快很多。 数据存储的稳定性往往通过"多存几份"的方式实现,HDFS 也使用了这种方式。HDFS 的存储单位是块 (Block) ,一个文件可能会被分为多个块储存在物理存储器中。因此 HDFS 往往会按照设定者的要求把数据块复制 n 份并存储在不同的数据节点 (储存数据的服务器) 上,如果一个数据节点发生故障数据也不会丢失。1.2 HDFS 的节点HDFS 运行在许多不同的计算机上,有的计算机专门用于存储数据,有的计算机专门用于指挥其它计算机储存数据。这里所提到的"计算机"我们可以称之为集群中的节点。1.3 命名节点 (NameNode)命名节点 (NameNode) 是用于指挥其它节点存储的节点。任何一个"文件系统"(File System, FS) 都需要具备根据文件路径映射到文件的功能,命名节点就是用于储存这些映射信息并提供映射服务的计算机,在整个 HDFS 系统中扮演"管理员"的角色,因此一个 HDFS 集群中只有一个命名节点。1.4 数据节点 (DataNode)数据节点 (DataNode) 使用来储存数据块的节点。当一个文件被命名节点承认并分块之后将会被储存到被分配的数据节点中去。数据节点具有储存数据、读写数据的功能,其中存储的数据块比较类似于硬盘中的"扇区"概念,是 HDFS 存储的基本单位。1.5 副命名节点 (Secondary NameNode)副命名节点 (Secondary NameNode) 别名"次命名节点",是命名节点的"秘书"。这个形容很贴切,因为它并不能代替命名节点的工作,无论命名节点是否有能力继续工作。它主要负责分摊命名节点的压力、备份命名节点的状态并执行一些管理工作,如果命名节点要求它这样做的话。如果命名节点坏掉了,它也可以提供备份数据以恢复命名节点。副命名节点可以有多个。二、MapReduceMapReduce 的含义就像它的名字一样浅显:Map 和 Reduce (映射和规约) 。2.1 大数据处理大量数据的处理是一个典型的"道理简单,实施复杂"的事情。之所以"实施复杂",主要是大量的数据使用传统方法处理时会导致硬件资源 (主要是内存) 不足。 现在有一段文字 (真实环境下这个字符串可能长达 1 PB 甚至更多) ,我们执行一个简单的"数字符"统计,即统计出这段文字中所有出现过的字符出现的数量: AABABCABCDABCDE 统计的过程实际上很简单,就是每读取一个字符就要检查表中是否已经有相同的字符,如果没有就添加一条记录并将记录值设置为 1 ,如果有的话就直接将记录值增加 1。 但是如果我们将这里的统计对象由"字符"变成"词",那么样本容量就瞬间变得非常大,以至于一台计算机可能难以统计数十亿用户一年来用过的"词"。 在这种情况下我们依然有办法完成这项工作——我们先把样本分成一段段能够令单台计算机处理的规模,然后一段段地进行统计,每执行完一次统计就对映射统计结果进行规约处理,即将统计结果合并到一个更庞大的数据结果中去,最终就可以完成大规模的数据规约。 在以上的案例中,第一阶段的整理工作就是"映射",把数据进行分类和整理,到这里为止,我们可以得到一个相比于源数据小很多的结果。第二阶段的工作往往由集群来完成,整理完数据之后,我们需要将这些数据进行总体的归纳,毕竟有可能多个节点的映射结果出现重叠分类。这个过程中映射的结果将会进一步缩略成可获取的统计结果。2.2 MapReduce 概念我在 IBM 的网站上找到了一篇 MapReduce 文章,地址:https://www.ibm.com/analytics/hadoop/mapreduce 。现在我改编其中的一个 MapReduce 的处理案例来介绍 MapReduce 的原理细节以及相关概念。 这是一个非常简单的 MapReduce 示例。无论需要分析多少数据,关键原则都是相同的。 假设有 5 个文件,每个文件包含两列,分别记录一个城市的名称以及该城市在不同测量日期记录的相应温度。城市名称是键 (Key) ,温度是值 (Value) 。例如:(厦门,20)。现在我们要在所有数据中找到每个城市的最高温度 (请注意,每个文件中可能出现相同的城市)。 使用 MapReduce 框架,我们可以将其分解为 5 个映射任务,其中每个任务负责处理五个文件中的一个。每个映射任务会检查文件中的每条数据并返回该文件中每个城市的最高温度。 例如,对于以下数据:
-
1.0 Hadoop 入门 一、Hadoop是什么?有什么用?Hadoop 是一个开源的分布式计算和存储框架,由 Apache 基金会开发和维护。 Hadoop 为庞大的计算机集群提供可靠的、可伸缩的应用层计算和存储支持,它允许使用简单的编程模型跨计算机群集分布式处理大型数据集,并且支持在单台计算机到几千台计算机之间进行扩展。 Hadoop 使用 Java 开发,所以可以在多种不同硬件平台的计算机上部署和使用。其核心部件包括分布式文件系统 (Hadoop DFS,HDFS) 和 MapReduce。Hadoop 的作用非常简单,就是在多计算机集群环境中营造一个统一而稳定的存储和计算环境,并能为其他分布式应用服务提供平台支持。 也就是说, Hadoop 在某种程度上将多台计算机组织成了一台计算机(做同一件事),那么 HDFS 就相当于这台计算机的硬盘,而 MapReduce 就是这台计算机的 CPU 控制器。二、Hadoop 运行环境 2.1 为什么要用docker部署由于 Hadoop 是为集群设计的软件,所以我们在学习它的使用时难免会遇到在多台计算机上配置 Hadoop 的情况,这对于学习者来说会制造诸多障碍,主要有两个: - 昂贵的计算机集群。多计算机构成的集群环境需要昂贵的硬件. - 难以部署和维护。在众多计算机上部署相同的软件环境是一个大量的工作,而且非常不灵活,难以在环境更改后重新部署。 为了解决这些问题,我们有一个非常成熟的方式 Docker。 Docker 是一个容器管理系统,它可以向虚拟机一样运行多个"虚拟机"(容器),并构成一个集群。因为虚拟机会完整的虚拟出一个计算机来,所以会消耗大量的硬件资源且效率低下,而 Docker 仅提供一个独立的、可复制的运行环境,实际上容器中所有进程依然在主机上的内核中被执行,因此它的效率几乎和主机上的进程一样(接近100%)。2.2 Docker 部署#进入 Docker 命令行之后,拉取一个 Linux 镜像作为 Hadoop 运行的环境,这里推荐使用 CentOS 镜像(Debian 和其它镜像暂时会出现一些问题)。 docker pull centos:8#创建容器 Hadoop 支持在单个设备上运行,主要有两种模式:单机模式和伪集群模式。 本章讲述 Hadoop 的安装与单机模式。#配置 Java 与 SSH 环境 现在创建一个容器,名为 java_ssh_proto,用于配置一个包含 Java 和 SSH 的环境: docker run -d --name=java_ssh_proto --privileged centos:8 /usr/sbin/init #然后进入容器: docker exec -it java_ssh_proto bash# 1) 修复 DNS(容器内临时生效;宿主可用 docker --dns 永久设定) echo -e 'nameserver 1.1.1.1\nnameserver 8.8.8.8' > /etc/resolv.conf # 2) 把 CentOS Linux 8 的 repo 指向 USTC 的 vault(8.5.2111 是最终版本) sed -ri \ -e 's|^mirrorlist=|#mirrorlist=|g' \ -e 's|^#baseurl=http://mirror.centos.org/\$contentdir/\$releasever|baseurl=https://mirrors.ustc.edu.cn/centos-vault/8.5.2111|g' \ /etc/yum.repos.d/CentOS-Linux-*.repo # (可选)如果想用官方 vault,把上面的 baseurl 换成: # https://vault.centos.org/8.5.2111 # 3) 更新缓存并安装 yum clean all yum makecache --refresh yum install -y java-1.8.0-openjdk-devel openssh-clients openssh-server systemctl enable sshd && systemctl start sshd #如果是 ubuntu 系统,使用以下命令启动 SSH 服务: #systemctl enable ssh && systemctl start ssh#报错镜像 docker stop java_ssh_proto docker commit java_ssh_proto java_ssh三、Hadoop 安装 3.1 下载hadoopHadoop 官网地址:http://hadoop.apache.org/ Hadoop 发行版本下载:https://hadoop.apache.org/releases.html 3.2 创建 Hadoop 单机容器#将下载好的 hadoop 压缩包拷贝到容器中的 /root 目录下: docker cp <你存放hadoop压缩包的路径> hadoop_single:/root/ #进入容器: docker exec -it hadoop_single bash #进入 /root 目录: cd /root #这里应该存放着刚刚拷贝过来的 hadoop-x.x.x.tar.gz 文件,现在解压它: tar -zxf hadoop-3.4.2.tar.gz mv ./hadoop-3.4.2 /usr/local/hadoop ln -sfn /usr/local/hadoop-3.4.2 /usr/local/hadoop # RHEL/CentOS/Alma/Rocky yum install -y java-11-openjdk-devel || dnf install -y java-11-openjdk-devel # 验证 java -version javac -version #现在以之前保存的 java_ssh 镜像创建容器 hadoop_single: docker run -d --name=hadoop_single --privileged java_ssh /usr/sbin/init #重写 /etc/profile.d/hadoop.sh(去掉 which) cat >/etc/profile.d/hadoop.sh <<'EOF' export HADOOP_HOME=/usr/local/hadoop # 自动探测 JAVA_HOME(优先用 javac,退而求其次用 java) if command -v javac >/dev/null 2>&1; then JBIN="$(readlink -f "$(command -v javac)")" elif command -v java >/dev/null 2>&1; then JBIN="$(readlink -f "$(command -v java)")" fi if [ -n "$JBIN" ]; then # 去掉末尾的 /bin/xxx,得到上两级目录作为 JAVA_HOME export JAVA_HOME="${JBIN%/bin/*}" fi export PATH="$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin" EOF # 使其生效 source /etc/profile.d/hadoop.sh # 验证探测结果 [root@596e7bed5026 ~]# echo "$JAVA_HOME" /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.312.b07-2.el8_5.x86_64 # 让 Hadoop 继承我们环境中的 JAVA_HOME echo 'export JAVA_HOME=${JAVA_HOME}' >> "$HADOOP_HOME/etc/hadoop/hadoop-env.sh" #测试 [root@596e7bed5026 hadoop]# hadoop version Hadoop 3.4.2 Source code repository https://github.com/apache/hadoop.git -r 84e8b89ee2ebe6923691205b9e171badde7a495c Compiled by ahmarsu on 2025-08-20T10:30Z Compiled on platform linux-x86_64 Compiled with protoc 3.23.4 From source with checksum fa94c67d4b4be021b9e9515c9b0f7b6 This command was run using /usr/local/hadoop-3.4.2/share/hadoop/common/hadoop-common-3.4.2.jar