搜索到
156
篇与
的结果
-
 redis集群升级 总结升级redis 中间件的过程一、备份二、修改yal文件 更改镜像三、直接docker-compose up <容器的名字> 注意需要先升级slave再升级maste节点四、查看状态redis-cli -p 6001 -a <密码> info replication | egrep 'role|connected_slaves'root@37d65a2680e6:/data# redis-cli -c -p 6001 -a <密码> cluster info | egrep 'cluster_state|cluster_slots_ok|cluster_slots_fail'Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.cluster_state:okcluster_slots_ok:16384cluster_slots_fail:0
redis集群升级 总结升级redis 中间件的过程一、备份二、修改yal文件 更改镜像三、直接docker-compose up <容器的名字> 注意需要先升级slave再升级maste节点四、查看状态redis-cli -p 6001 -a <密码> info replication | egrep 'role|connected_slaves'root@37d65a2680e6:/data# redis-cli -c -p 6001 -a <密码> cluster info | egrep 'cluster_state|cluster_slots_ok|cluster_slots_fail'Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.cluster_state:okcluster_slots_ok:16384cluster_slots_fail:0 -
esxi加硬盘 一、先给虚拟机加上硬盘 二、在虚拟机中识别 2.1 扫描SCSI总线以添加新设备在Linux系统中,尤其是虚拟化环境(如VMware, KVM, VirtualBox),新添加的SCSI硬盘可以通过触发系统重新扫描SCSI主机总线来识别。#首先,查看当前已连接的SCSI主机总线编号: ls /sys/class/scsi_host/#强制系统重新扫描所有的SCSI主机总线: echo "- - -" | sudo tee /sys/class/scsi_host/host*/scan#验证新硬盘是否被识别: lsblk2.2 加入扩容整个流程分为四步:创建物理卷 -> 扩展卷组 -> 扩展逻辑卷 -> 扩展文件系统。#将新磁盘 /dev/sdb 初始化为 LVM 物理卷 (PV) sudo pvcreate /dev/sdb #这条命令相当于告诉 LVM:“这块新磁盘交给你来管理”。 # Physical volume "/dev/sdb" successfully created.#将新的物理卷扩展到名为 rl的卷组 (VG) 中 sudo vgextend rl /dev/sdb #这条命令相当于把新来的“员工”(PV /dev/sdb)分配到了现有的“部门”(VG rl)里。现在这个部门就有了额外的100G“人力”(空间)。 #Volume group "rl" successfully extended#查看卷组确认空间,并扩展逻辑卷 (LV) sudo vgs # VSize(总大小) 变大了,并且 VFree(剩余空间) 这里显示了加入的 ~100G 空间。#方案A:将所有空闲空间都给 root sudo lvextend -l +100%FREE /dev/mapper/rl-root#方案B:只扩展指定大小(例如 50G) sudo lvextend -L +50G /dev/mapper/rl-root
-
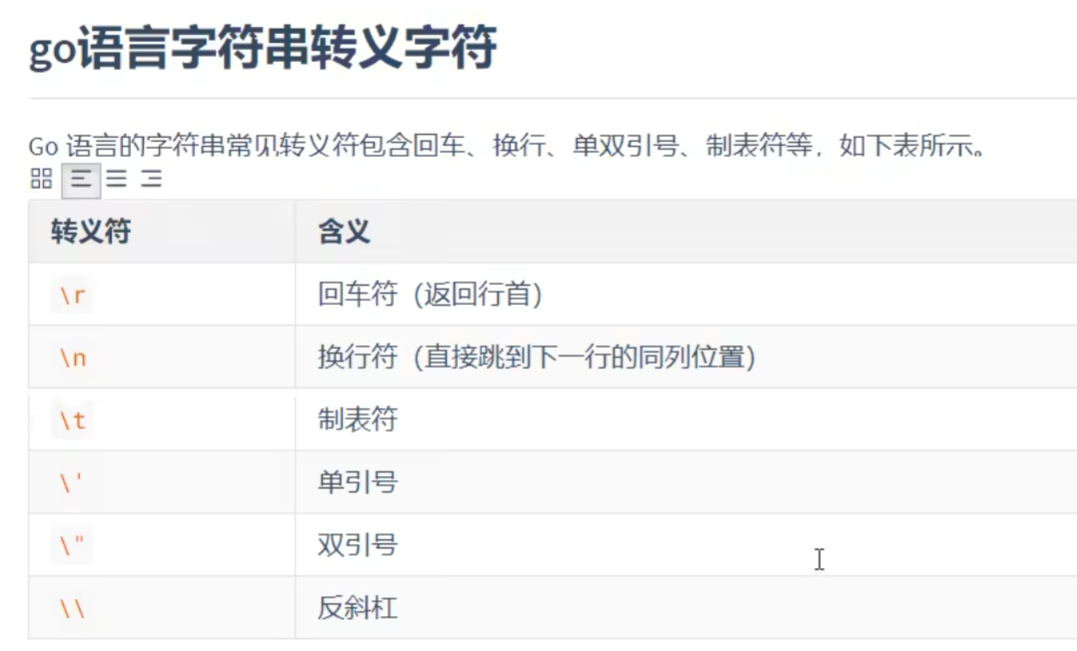
字符串拼接 一、字符串拼接 1.1 + 运算s2 := s1 + name优点:最直观,少量片段时也最快。单个表达式里 a + b + c 编译器会预估长度、仅一次分配。 注意:在循环中做 s += part 会导致多次分配与拷贝(可能退化 O(n^2)),应改为 Builder/Buffer 或先收集后 Join。 适用:2–5 个固定小片段、对性能要求一般的场景;常量拼接会在编译期完成(零开销)。1.2 strings.Joind4 := strings.Join([]string{d1, d2}, ",")优点:已在切片里、有统一分隔符(如 ,、|、空串)时,一次性预分配,通常是多段连接的首选。 适用:CSV/日志行拼接、URL path/标签列表、SQL 占位符 "?,?,?" 之类模式。 小技巧:先 make([]string, 0, n) 收集,再 strings.Join(parts, sep) 可减少切片扩容。1.3 fmt.Sprintfd3 := fmt.Sprintf("%s,%s", d1, d2)// 优点:格式化强、跨类型方便(%d、%.2f、对齐宽度等)。 // 缺点:需要解析格式串,最慢、分配也更多。 // 适用:确实需要格式化能力(尤其跨类型)时;在性能敏感路径尽量用 strconv/Builder 代替: var b strings.Builder b.WriteString(name) b.WriteByte(',') b.WriteString(strconv.Itoa(age)) s := b.String()1.4 bytes.Buffervar buffer bytes.Buffer buffer.WriteString("tom") buffer.WriteString(",") buffer.WriteString("20") s := buffer.String()优点:实现了 io.Writer,与其它 Writer/Reader 组合很方便,既可写字符串也可写字节。 注意:buffer.String() 会拷贝内部 []byte 生成字符串(因此会有一次分配)。 适用:需要同时处理 []byte、或与文件/网络/压缩流等 IO 组件对接时;如果最终只要 string,通常改用 strings.Builder 更省。1.5 strings.Buildervar sb strings.Builder sb.Grow(64) // 可选:大致预估长度 sb.WriteString("tom") sb.WriteByte(',') sb.WriteString("20") s := sb.String() // 通常零拷贝拿到字符串优点:零值可用;为构造字符串而生,String() 返回结果通常不拷贝底层数据;也实现 io.Writer。 注意:不要拷贝已使用过的 Builder(按值传递会出问题);非并发安全。 适用:循环里逐步构建字符串、性能敏感路径、最终产出是 string 的情况。二、常见场景的推荐写法 2.1 循环里累计很多片段(性能敏感)//用 strings.Builder 或 bytes.Buffer(只要字符串就用 Builder) var b strings.Builder b.Grow(1024) // 如果能粗略估计长度 for _, p := range parts { b.WriteString(p) b.WriteByte(',') } s := b.String()2.2 已有切片 + 统一分隔符 (用 strings.Join)s := strings.Join(parts, ",")2.3 少量固定片段 用 +s := "hello " + name2.4 需要格式化/跨类型// 用 fmt.Sprintf(或 strconv + Builder 更高性能) s := fmt.Sprintf("%s(%d)", name, age) // 或 var b strings.Builder b.WriteString(name) b.WriteByte('(') b.WriteString(strconv.Itoa(age)) b.WriteByte(')') s := b.String()2.5 小坑与小技巧- +/Sprintf 都不适合在大循环内反复累加;会频繁分配。 - strings.Builder/bytes.Buffer 都不是并发安全;不要在多个 goroutine 同时写。 - strings.Builder 的实例不要复制(作为函数参数请传指针或在内部新建)。 - bytes.Buffer 的 String() 每次都会生成新字符串;避免在热路径里对同一个 Buffer 反复 String()。 - 需要固定宽度、小数位、对齐等格式控制时,fmt 家族清晰可读;对极致性能,优先 strconv.Append* 系列 + Builder/Buffer。三、转义字符
-
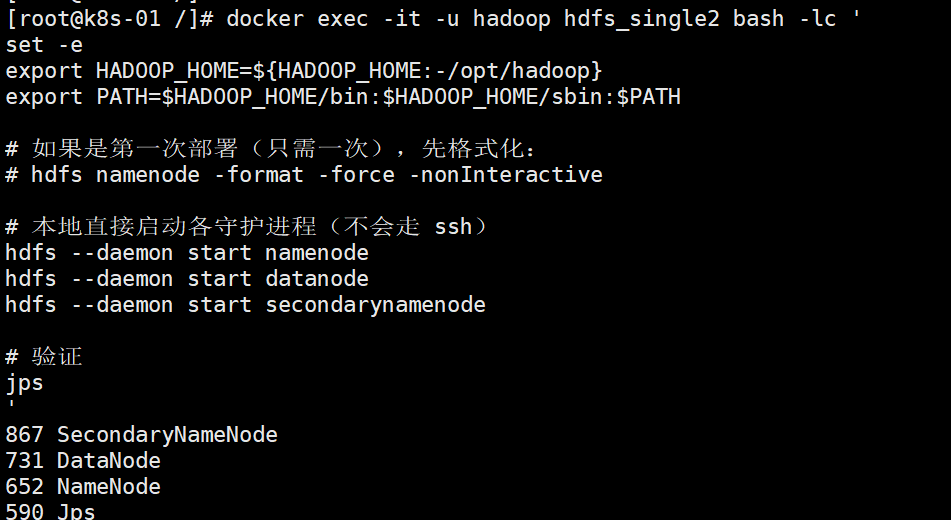
4.0 HDFS 集群 一、准备工作HDFS 集群是建立在 Hadoop 集群之上的,由于 HDFS 是 Hadoop 最主要的守护进程,所以 HDFS 集群的配置过程是 Hadoop 集群配置过程的代表。 使用 Docker 可以更加方便地、高效地构建出一个集群环境。1.1 做hosts#三台机的hosts文件要提前做好 我这里因为是k8s节点已经提前做好了 [root@k8s-01 ~]# cat /etc/hosts 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.30.50 k8s-01 192.168.30.51 k8s-02 192.168.30.52 k8s-03 192.168.30.58 k8s-vip 192.168.30.50 goodrain.me1.2 做镜像# 在 k8s-01 上 docker save hadoop_proto:with-hdfs -o /root/hadoop_proto_with_hdfs.tar scp /root/hadoop_proto_with_hdfs.tar root@192.168.30.51:/root/ scp /root/hadoop_proto_with_hdfs.tar root@192.168.30.52:/root/ # 在 k8s-02、k8s-03 分别执行 docker load -i /root/hadoop_proto_with_hdfs.tar docker images | grep hadoop_proto1.3 在 k8s-02/03 为 DataNode 准备持久化目录(建议开始用宿主机目录做持久化,避免容器删掉后数据/元数据丢失) # k8s-02 mkdir -p /data/hdfs/datanode # k8s-03 mkdir -p /data/hdfs/datanode #如果容器里运行用户是 hadoop,建议给目录授权: #chown -R 1000:1000 /data/hdfs/datanode # 1000 常见是 hadoop 用户 UID,如不同再调整1.4 在 k8s-02/03 只启动 DataNode(不要再起 NameNode)方式 A:host 网络 + 覆盖 DN 配置 + 只拉起 DN # k8s-02 docker run -d \ --name hdfs-dn-02 \ --hostname hdfs-dn-02 \ --network host \ -v /data/hdfs/datanode:/usr/local/hadoop/dfs/data \ hadoop_proto:with-hdfs \ bash set -e # 1) 写入 DataNode 专用的 hdfs-site.xml(指明对外通告的主机IP) cat >/usr/local/hadoop/etc/hadoop/hdfs-site.xml << "EOF" <?xml version="1.0" encoding="UTF-8"?> <configuration> <property><name>dfs.datanode.data.dir</name><value>file:///usr/local/hadoop/dfs/data</value></property> <!-- 集群副本策略:沿用 3,也可以先设 2/1 过渡 --> <property><name>dfs.replication</name><value>3</value></property> <!-- DataNode 对外通告的地址=宿主机IP --> <property><name>dfs.datanode.use.datanode.hostname</name><value>true</value></property> <property><name>dfs.datanode.hostname</name><value>192.168.30.51</value></property> <!-- 监听地址 --> <property><name>dfs.datanode.address</name><value>0.0.0.0:9866</value></property> <property><name>dfs.datanode.http.address</name><value>0.0.0.0:9864</value></property> <property><name>dfs.datanode.ipc.address</name><value>0.0.0.0:9867</value></property> </configuration> EOF # 2) core-site.xml 保持指向 NameNode(192.168.30.50:9000) # 如果镜像里已经是这个值就不用动;保险起见再写一次: cat >/usr/local/hadoop/etc/hadoop/core-site.xml << "EOF" <?xml version="1.0" encoding="UTF-8"?> <configuration> <property><name>fs.defaultFS</name><value>hdfs://192.168.30.50:9000</value></property> <property><name>dfs.client.use.datanode.hostname</name><value>true</value></property> </configuration> EOF # 3) 只启动 DataNode /usr/local/hadoop/bin/hdfs --daemon start datanode # 4) 挂住容器(观察日志) tail -F /usr/local/hadoop/logs/*datanode*.log1.5 在 k8s-01 修改配置[hadoop@80b2f403b24e hadoop]$ cat ./core-site.xml <?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name>fs.defaultFS</name> <value>hdfs://192.168.30.50:9000</value> </property> <property> <name>dfs.client.use.datanode.hostname</name> <value>true</value> </property> </configuration> [hadoop@80b2f403b24e hadoop]$ cat ./hdfs-site.xml <?xml version="1.0" encoding="UTF-8"?> <configuration> <!-- NameNode / DataNode 本机目录 --> <property><name>dfs.namenode.name.dir</name><value>file:///usr/local/hadoop/dfs/name</value></property> <property><name>dfs.datanode.data.dir</name><value>file:///usr/local/hadoop/dfs/data</value></property> <property><name>dfs.replication</name><value>3</value></property> <!-- NN 监听与对外地址 --> <property><name>dfs.namenode.rpc-address</name><value>192.168.30.50:9000</value></property> <property><name>dfs.namenode.rpc-bind-host</name><value>0.0.0.0</value></property> <property><name>dfs.namenode.http-address</name><value>192.168.30.50:9870</value></property> <property><name>dfs.namenode.http-bind-host</name><value>0.0.0.0</value></property> <!-- 客户端/DN 使用主机名(或指定IP)模式 --> <property><name>dfs.client.use.datanode.hostname</name><value>true</value></property> <!-- 关键:放宽 NN 对 DN 注册时的 IP/主机名一致性校验 --> <property> <name>dfs.namenode.datanode.registration.ip-hostname-check</name> <value>false</value> </property> <!-- 本机若同时跑 DN,以下配置保留 --> <property><name>dfs.datanode.use.datanode.hostname</name><value>true</value></property> <property><name>dfs.datanode.hostname</name><value>192.168.30.50</value></property> <property><name>dfs.datanode.address</name><value>0.0.0.0:9866</value></property> <property><name>dfs.datanode.http.address</name><value>0.0.0.0:9864</value></property> <property><name>dfs.datanode.ipc.address</name><value>0.0.0.0:9867</value></property> </configuration> #如果是从我之前单节点执行过来的 可以执行下面的命令修改 也可以直接复制上面的命令修改 # 进入配置目录 cd /usr/local/hadoop/etc/hadoop # 备份 sudo cp -a hdfs-site.xml hdfs-site.xml.bak.$(date +%s) # 用 sudo tee 覆盖写入(注意:这里是覆盖而不是追加) sudo tee hdfs-site.xml >/dev/null <<'EOF' <?xml version="1.0" encoding="UTF-8"?> <configuration> <!-- NameNode / DataNode 本机目录 --> <property><name>dfs.namenode.name.dir</name><value>file:///usr/local/hadoop/dfs/name</value></property> <property><name>dfs.datanode.data.dir</name><value>file:///usr/local/hadoop/dfs/data</value></property> <property><name>dfs.replication</name><value>3</value></property> <!-- NN 监听与对外地址 --> <property><name>dfs.namenode.rpc-address</name><value>192.168.30.50:9000</value></property> <property><name>dfs.namenode.rpc-bind-host</name><value>0.0.0.0</value></property> <property><name>dfs.namenode.http-address</name><value>192.168.30.50:9870</value></property> <property><name>dfs.namenode.http-bind-host</name><value>0.0.0.0</value></property> <!-- 客户端/DN 使用主机名(或指定IP)模式 --> <property><name>dfs.client.use.datanode.hostname</name><value>true</value></property> <!-- 关键:放宽 NN 对 DN 注册时的 IP/主机名一致性校验 --> <property> <name>dfs.namenode.datanode.registration.ip-hostname-check</name> <value>false</value> </property> <!-- 本机若同时跑 DN,以下配置保留 --> <property><name>dfs.datanode.use.datanode.hostname</name><value>true</value></property> <property><name>dfs.datanode.hostname</name><value>192.168.30.50</value></property> <property><name>dfs.datanode.address</name><value>0.0.0.0:9866</value></property> <property><name>dfs.datanode.http.address</name><value>0.0.0.0:9864</value></property> <property><name>dfs.datanode.ipc.address</name><value>0.0.0.0:9867</value></property> </configuration> EOF1.6 重启# 重启 NameNode(以及本机 DataNode 让新配置生效) /usr/local/hadoop/bin/hdfs --daemon stop namenode sleep 2 /usr/local/hadoop/bin/hdfs --daemon start namenode /usr/local/hadoop/bin/hdfs --daemon stop datanode sleep 2 /usr/local/hadoop/bin/hdfs --daemon start datanode二、验证 2.1 在k8s-02/03 中确认 DN 监听正确端口(9864/9866/9867)且用宿主机 IP 对外通告# DN 是否在监听 9864/9866/9867 [root@hdfs-dn-02 tmp]# ss -lntp | egrep ':(9864|9866|9867)\b' || netstat -lntp | egrep ':(9864|9866|9867)\b' LISTEN 0 4096 0.0.0.0:9864 0.0.0.0:* users:(("java",pid=60,fd=389)) LISTEN 0 256 0.0.0.0:9867 0.0.0.0:* users:(("java",pid=60,fd=390)) LISTEN 0 256 0.0.0.0:9866 0.0.0.0:* users:(("java",pid=60,fd=333)) # 再从 NN 容器主动连过来测 DN 的 9867(IPC)和 9866(数据)是否可达 # 在 NN 容器执行下面两条,分别测 51/52: [root@hdfs-dn-02 tmp]# bash -lc 'echo > /dev/tcp/192.168.30.51/9867 && echo OK-51-9867 || echo FAIL' OK-51-9867 [root@hdfs-dn-02 tmp]# bash -lc 'echo > /dev/tcp/192.168.30.51/9866 && echo OK-51-9866 || echo FAIL' OK-51-9866 [root@hdfs-dn-02 tmp]# [root@hdfs-dn-02 tmp]# bash -lc 'echo > /dev/tcp/192.168.30.52/9867 && echo OK-52-9867 || echo FAIL' OK-52-9867 [root@hdfs-dn-02 tmp]# [root@hdfs-dn-02 tmp]# bash -lc 'echo > /dev/tcp/192.168.30.52/9866 && echo OK-52-9866 || echo FAIL' OK-52-9866 #如果这些端口不在监听,说明 DN 的 hdfs-site.xml 没生效或没用 host 网络。 #如果 FAIL,多半是 firewalld/iptables 拦了,放行 9864/9866/9867(DN)与 9000/9870(NN)。2.2 在k8s-01节点执行[hadoop@80b2f403b24e hadoop]$ hdfs dfsadmin -report Safe mode is ON Configured Capacity: 145030643712 (135.07 GB) Present Capacity: 92691496960 (86.33 GB) DFS Remaining: 92691451904 (86.33 GB) DFS Used: 45056 (44 KB) DFS Used%: 0.00% Replicated Blocks: Under replicated blocks: 0 Blocks with corrupt replicas: 0 Missing blocks: 0 Missing blocks (with replication factor 1): 0 Low redundancy blocks with highest priority to recover: 0 Pending deletion blocks: 0 Erasure Coded Block Groups: Low redundancy block groups: 0 Block groups with corrupt internal blocks: 0 Missing block groups: 0 Low redundancy blocks with highest priority to recover: 0 Pending deletion blocks: 0 ------------------------------------------------- Live datanodes (3): Name: 172.17.0.1:9866 (_gateway) Hostname: 192.168.30.50 Decommission Status : Normal Configured Capacity: 48343547904 (45.02 GB) DFS Used: 28672 (28 KB) Non DFS Used: 25802944512 (24.03 GB) DFS Remaining: 22540574720 (20.99 GB) DFS Used%: 0.00% DFS Remaining%: 46.63% Configured Cache Capacity: 0 (0 B) Cache Used: 0 (0 B) Cache Remaining: 0 (0 B) Cache Used%: 100.00% Cache Remaining%: 0.00% Xceivers: 0 Last contact: Sun Sep 21 14:40:41 UTC 2025 Last Block Report: Sun Sep 21 14:40:29 UTC 2025 Num of Blocks: 2 Name: 192.168.30.51:9866 (192.168.30.51) Hostname: 192.168.30.51 Decommission Status : Normal Configured Capacity: 48343547904 (45.02 GB) DFS Used: 8192 (8 KB) Non DFS Used: 12121690112 (11.29 GB) DFS Remaining: 36221849600 (33.73 GB) DFS Used%: 0.00% DFS Remaining%: 74.93% Configured Cache Capacity: 0 (0 B) Cache Used: 0 (0 B) Cache Remaining: 0 (0 B) Cache Used%: 100.00% Cache Remaining%: 0.00% Xceivers: 0 Last contact: Sun Sep 21 14:40:43 UTC 2025 Last Block Report: Sun Sep 21 14:40:19 UTC 2025 Num of Blocks: 0 Name: 192.168.30.52:9866 (192.168.30.52) Hostname: 192.168.30.52 Decommission Status : Normal Configured Capacity: 48343547904 (45.02 GB) DFS Used: 8192 (8 KB) Non DFS Used: 14414512128 (13.42 GB) DFS Remaining: 33929027584 (31.60 GB) DFS Used%: 0.00% DFS Remaining%: 70.18% Configured Cache Capacity: 0 (0 B) Cache Used: 0 (0 B) Cache Remaining: 0 (0 B) Cache Used%: 100.00% Cache Remaining%: 0.00% Xceivers: 0 Last contact: Sun Sep 21 14:40:43 UTC 2025 Last Block Report: Sun Sep 21 14:40:19 UTC 2025 Num of Blocks: 0 [hadoop@80b2f403b24e hadoop]$ hdfs dfsadmin -printTopology Rack: /default-rack 192.168.30.52:9866 (192.168.30.52) In Service 172.17.0.1:9866 (_gateway) In Service 192.168.30.51:9866 (192.168.30.51) In Service 2.3 测试#在k8s-01中插入内容 echo xing | hdfs dfs -appendToFile - /tmp/hello.txt #在k8s-01/02/03查看内容 hdfs dfs -cat /tmp/hello.txt [hadoop@80b2f403b24e hadoop]$ echo xing | hdfs dfs -appendToFile - /tmp/hello.txt [hadoop@80b2f403b24e hadoop]$ hdfs dfs -cat /tmp/hello.txt hello xing [root@hdfs-dn-02 tmp]# hdfs dfs -cat /tmp/hello.txt hello xing [root@hdfs-dn-03 tmp]# hdfs dfs -cat /tmp/hello.txt hello xing 2.4 节点开机自动拉起# 让 Docker 自启(若未开启) sudo systemctl enable --now docker # 给容器加重启策略:除非手动 stop,否则跟随宿主机重启而自动拉起 sudo docker update --restart unless-stopped hdfs_single2 # k8s-01 上的 NN(+DN) 容器名 sudo docker update --restart unless-stopped hdfs-dn-02 # k8s-02 DN sudo docker update --restart unless-stopped hdfs-dn-03 # k8s-03 DN # 验证 docker inspect -f '{{.HostConfig.RestartPolicy.Name}}' hdfs_single2 docker inspect -f '{{.HostConfig.RestartPolicy.Name}}' hdfs-dn-02 docker inspect -f '{{.HostConfig.RestartPolicy.Name}}' hdfs-dn-03 # 都应显示:unless-stopped2.5 优化后续要优化k8s-01节点HDFS数据挂载到宿主机 避免数据丢失 配置docker-compose 管理
-
3.0 HDFS 配置与使用 之前提到过的 Hadoop 三种模式:单机模式、伪集群模式和集群模式。 单机模式:Hadoop 仅作为库存在,可以在单计算机上执行 MapReduce 任务,仅用于开发者搭建学习和试验环境。 伪集群模式:此模式 Hadoop 将以守护进程的形式在单机运行,一般用于开发者搭建学习和试验环境。 集群模式:此模式是 Hadoop 的生产环境模式,也就是说这才是 Hadoop 真正使用的模式,用于提供生产级服务。一、HDFS 配置和启动HDFS 和数据库相似,是以守护进程的方式启动的。使用 HDFS 需要用 HDFS 客户端通过网络 (套接字) 连接到 HDFS 服务器实现文件系统的使用。 我们已经配置好了 Hadoop 的基础环境,容器名为 hadoop_single。如果你上次已经关闭了该容器或者关闭了计算机导致容器关闭,请启动并进入该容器。 进入该容器后,我们确认一下 Hadoop 是否存在: hadoop version #如果结果显示出 Hadoop 版本号则表示 Hadoop 存在。1.1 新建 hadoop 用户#新建用户,名为 hadoop: adduser hadoop #安装一个小工具用于修改用户密码和权限管理: yum install -y passwd sudo #设置 hadoop 用户密码 passwd hadoop #接下来两次输入密码,一定要记住! #修改 hadoop 安装目录所有人为 hadoop 用户: chown -R hadoop /usr/local/hadoop #然后用文本编辑器修改 /etc/sudoers 文件,在 root ALL=(ALL) ALL #之后添加一行 hadoop ALL=(ALL) ALL #然后退出容器。 #关闭并提交容器 hadoop_single 到镜像 hadoop_proto: docker stop hadoop_single docker commit hadoop_single hadoop_proto #创建新容器 hdfs_single : docker run -d --name=hdfs_single --privileged hadoop_proto /usr/sbin/init1.2 启动 HDFS#现在进入刚建立的容器: docker exec -it hdfs_single su hadoop #现在应该是 hadoop 用户: whoami #生成 SSH 密钥: ssh-keygen -t rsa #这里可以一直按回车直到生成结束。 #然后将生成的密钥添加到信任列表: ssh-copy-id hadoop@172.17.0.2 #查看容器 IP 地址: ip addr | grep 172 [hadoop@6eb1ec6bd5ce /]$ ip addr | grep 17 inet 172.17.0.2/16 brd 172.17.255.255 scope global eth0 #从而得知容器的 IP 地址是 172.17.0.2#在启动 HDFS 以前我们对其进行一些简单配置,Hadoop 配置文件全部储存在安装目录下的 etc/hadoop 子目录下,所以我们可以进入此目录: cd $HADOOP_HOME/etc/hadoop #这里我们修改两个文件:core-site.xml 和 hdfs-site.xml #在 core-site.xml 中,我们在 标签下添加属性: [hadoop@80b2f403b24e /]$ cd $HADOOP_HOME/etc/hadoop [hadoop@80b2f403b24e hadoop]$ pwd /usr/local/hadoop/etc/hadoop [hadoop@80b2f403b24e hadoop]$ cat ./core-site.xml <?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name>fs.defaultFS</name> <value>hdfs://192.168.30.50:9000</value> </property> </configuration> [hadoop@80b2f403b24e hadoop]$ [hadoop@80b2f403b24e hadoop]$ cat ./hdfs-site.xml <?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>dfs.namenode.name.dir</name> <value>file:///usr/local/hadoop/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:///usr/local/hadoop/dfs/data</value> </property> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.rpc-address</name> <value>192.168.30.50:9000</value> </property> <property> <name>dfs.namenode.rpc-bind-host</name> <value>0.0.0.0</value> </property> <property> <name>dfs.namenode.http-address</name> <value>192.168.30.50:9870</value> </property> <property> <name>dfs.namenode.http-bind-host</name> <value>0.0.0.0</value> </property> <property> <name>dfs.client.use.datanode.hostname</name> <value>true</value> </property> <property> <name>dfs.datanode.use.datanode.hostname</name> <value>true</value> </property> <property> <name>dfs.datanode.hostname</name> <value>192.168.30.50</value> </property> <property> <name>dfs.datanode.address</name> <value>0.0.0.0:9866</value> </property> <property> <name>dfs.datanode.http.address</name> <value>0.0.0.0:9864</value> </property> </configuration> # 建日志与数据目录 sudo mkdir -p /usr/local/hadoop/logs sudo mkdir -p /usr/local/hadoop/dfs/{name,data} # 把这些目录交给 hadoop 用户 sudo chown -R hadoop:hadoop /usr/local/hadoop/logs sudo chown -R hadoop:hadoop /usr/local/hadoop/dfsdocker stop hdfs_single [root@k8s-01 /]# docker run -d --name hdfs_single2 \ --privileged --cgroupns=host \ -v /sys/fs/cgroup:/sys/fs/cgroup:ro \ -p 9870:9870 \ -p 9000:9000 \ -p 9864:9864 \ -p 9866:9866 \ hadoop_proto:with-hdfs /usr/sbin/init 80b2f403b24eb1458cc2dbc852eeb50a46119f4f355f5a7ba0c204b32e288486 到此为止,HDFS 守护进程已经建立,由于 HDFS 本身具备 HTTP 面板,我们可以通过浏览器访问http://你的节点IP:9870/来查看 HDFS 面板以及详细信息:二、HDFS 使用 2.1 HDFS Shell#回到 hdfs_single 容器,以下命令将用于操作 HDFS: # 显示根目录 / 下的文件和子目录,绝对路径 hadoop fs -ls / # 新建文件夹,绝对路径 hadoop fs -mkdir /hello # 上传文件 hadoop fs -put hello.txt /hello/ # 下载文件 hadoop fs -get /hello/hello.txt # 输出文件内容 hadoop fs -cat /hello/hello.txt #HDFS 最基础的命令如上所述,除此之外还有许多其他传统文件系统所支持的操作。2.2 HDFS APIHDFS 已经被很多的后端平台所支持,目前官方在发行版中包含了 C/C++ 和 Java 的编程接口。此外,node.js 和 Python 语言的包管理器也支持导入 HDFS 的客户端。 以下是包管理器的依赖项列表: Maven: <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>3.1.4</version> </dependency> Gradle: providedCompile group: 'org.apache.hadoop', name: 'hadoop-hdfs-client', version: '3.1.4' NPM: npm i webhdfs pip: pip install hdfs#这里提供一个 Java 连接 HDFS 的例子(别忘了修改 IP 地址): package com.runoob; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.*; public class Application { public static void main(String[] args) { try { // 配置连接地址 Configuration conf = new Configuration(); conf.set("fs.defaultFS", "hdfs://172.17.0.2:9000"); FileSystem fs = FileSystem.get(conf); // 打开文件并读取输出 Path hello = new Path("/hello/hello.txt"); FSDataInputStream ins = fs.open(hello); int ch = ins.read(); while (ch != -1) { System.out.print((char)ch); ch = ins.read(); } System.out.println(); } catch (IOException ioe) { ioe.printStackTrace(); } } }