搜索到
154
篇与
的结果
-
 3.0 Zookeeper linux 服务端集群搭建步骤 1、准备三台 zookeeper 环境和并按照上一教程下载 zookeeper 压缩包,三台集群 centos 环境如下:192.168.30.50 192.168.30.51 192.168.30.522、别修改 zoo.cfg 配置信息zookeeper 的三个端口作用 1、2181 : 对 client 端提供服务 2、2888 : 集群内机器通信使用 3、3888 : 选举 leader 使用 按 server.id = ip:port:port 修改集群配置文件: 三台虚拟机 zoo.cfg 文件末尾添加配置: server.1=192.168.30.50:2888:3888 server.2=192.168.30.51:2888:3888 server.3=192.168.30.52:2888:3888 # 三台都先确保目录存在且干净 mkdir -p /tmp/zookeeper rm -rf /tmp/zookeeper/* # 在 192.168.30.50 上: echo 1 > /tmp/zookeeper/myid # 在 192.168.30.51 上: echo 2 > /tmp/zookeeper/myid # 在 192.168.30.52 上: echo 3 > /tmp/zookeeper/myid 3、启动#确保端口互通且未被占用 systemctl stop firewalld #另外再确认端口未被其他进程占用: ss -lntp | egrep '(:2181|:2888|:3888)' #依次在三台上启动(顺序随意,但至少要起来 2 台才会过半): [root@k8s-01 bin]# bash ./zkServer.sh status ZooKeeper JMX enabled by default Using config: /root/zookeeper/apache-zookeeper-3.8.4-bin/bin/../conf/zoo.cfg Client port found: 2181. Client address: localhost. Client SSL: false. Mode: standalone [root@k8s-02 bin]# bash ./zkServer.sh status ZooKeeper JMX enabled by default Using config: /root/zookeeper/apache-zookeeper-3.8.4-bin/bin/../conf/zoo.cfg Client port found: 2181. Client address: localhost. Client SSL: false. Mode: follower [root@k8s-03 bin]# bash ./zkServer.sh status ZooKeeper JMX enabled by default Using config: /root/zookeeper/apache-zookeeper-3.8.4-bin/bin/../conf/zoo.cfg Client port found: 2181. Client address: localhost. Client SSL: false. Mode: leader
3.0 Zookeeper linux 服务端集群搭建步骤 1、准备三台 zookeeper 环境和并按照上一教程下载 zookeeper 压缩包,三台集群 centos 环境如下:192.168.30.50 192.168.30.51 192.168.30.522、别修改 zoo.cfg 配置信息zookeeper 的三个端口作用 1、2181 : 对 client 端提供服务 2、2888 : 集群内机器通信使用 3、3888 : 选举 leader 使用 按 server.id = ip:port:port 修改集群配置文件: 三台虚拟机 zoo.cfg 文件末尾添加配置: server.1=192.168.30.50:2888:3888 server.2=192.168.30.51:2888:3888 server.3=192.168.30.52:2888:3888 # 三台都先确保目录存在且干净 mkdir -p /tmp/zookeeper rm -rf /tmp/zookeeper/* # 在 192.168.30.50 上: echo 1 > /tmp/zookeeper/myid # 在 192.168.30.51 上: echo 2 > /tmp/zookeeper/myid # 在 192.168.30.52 上: echo 3 > /tmp/zookeeper/myid 3、启动#确保端口互通且未被占用 systemctl stop firewalld #另外再确认端口未被其他进程占用: ss -lntp | egrep '(:2181|:2888|:3888)' #依次在三台上启动(顺序随意,但至少要起来 2 台才会过半): [root@k8s-01 bin]# bash ./zkServer.sh status ZooKeeper JMX enabled by default Using config: /root/zookeeper/apache-zookeeper-3.8.4-bin/bin/../conf/zoo.cfg Client port found: 2181. Client address: localhost. Client SSL: false. Mode: standalone [root@k8s-02 bin]# bash ./zkServer.sh status ZooKeeper JMX enabled by default Using config: /root/zookeeper/apache-zookeeper-3.8.4-bin/bin/../conf/zoo.cfg Client port found: 2181. Client address: localhost. Client SSL: false. Mode: follower [root@k8s-03 bin]# bash ./zkServer.sh status ZooKeeper JMX enabled by default Using config: /root/zookeeper/apache-zookeeper-3.8.4-bin/bin/../conf/zoo.cfg Client port found: 2181. Client address: localhost. Client SSL: false. Mode: leader -
2.0 Zookeeper 安装配置 一、Linux 安装zookeeper 下载地址为: https://zookeeper.apache.org/releases.html。打开链接:https://www.apache.org/dyn/closer.lua/zookeeper/zookeeper-3.9.4/apache-zookeeper-3.9.4-bin.tar.gz需要有java的环境 建议使用java17 # 新系统优先 17 Zookeeper 不需要图形相关包,建议只装 headless,避免拉一堆 GUI 依赖。 dnf install -y java-17-openjdk-headless #确认 java 已安装 which java java -version #设置 JAVA_HOME(通用、稳妥) export JAVA_HOME="$(dirname "$(dirname "$(readlink -f "$(which java)")")")" echo "export JAVA_HOME=$JAVA_HOME" > /etc/profile.d/java.sh echo 'export PATH=$JAVA_HOME/bin:$PATH' >> /etc/profile.d/java.sh source /etc/profile.d/java.sh # 验证 echo "$JAVA_HOME" ls "$JAVA_HOME/bin/java" #启动 Zookeeper cd /path/to/zookeeper/bin bash ./zkServer.sh start 选择一个下载地址,使用 wget 命令下载并安装: $ wget https://www.apache.org/dyn/closer.lua/zookeeper/zookeeper-3.9.4/apache-zookeeper-3.9.4-bin.tar.gz $ tar -zxvf apache-zookeeper-3.9.4-bin.tar.gz $ cd apache-zookeeper-3.9.4 $ cd conf/ $ cp zoo_sample.cfg zoo.cfg $ cd .. $ cd bin/ #执行后,服务端启动成功: $ [root@k8s-01 bin]# bash ./zkServer.sh start ZooKeeper JMX enabled by default Using config: /root/zookpeeper/apache-zookeeper-3.8.4-bin/bin/../conf/zoo.cfg Starting zookeeper ... STARTED #查看服务端状态(启动单机节点): [root@k8s-01 bin]# bash ./zkServer.sh status ZooKeeper JMX enabled by default Using config: /root/zookpeeper/apache-zookeeper-3.8.4-bin/bin/../conf/zoo.cfg Client port found: 2181. Client address: localhost. Client SSL: false. Mode: standalone #启动客户端 sh zkCli.sh二、win安装略
-
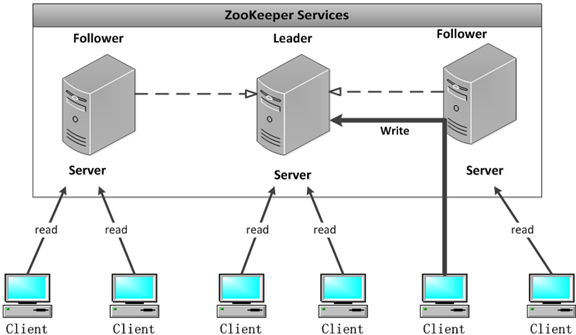
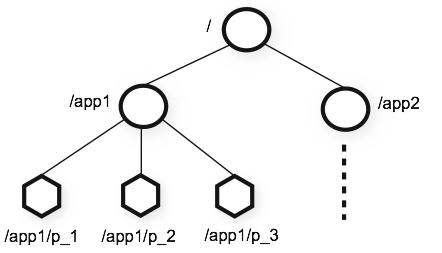
1.0 Zookeeper 介绍 一、zookeeper是什么?ZooKeeper 是 Apache 软件基金会的一个软件项目,它为大型分布式计算提供开源的分布式配置服务、同步服务和命名注册。 ZooKeeper 的架构通过冗余服务实现高可用性。 Zookeeper 的设计目标是将那些复杂且容易出错的分布式一致性服务封装起来,构成一个高效可靠的原语集,并以一系列简单易用的接口提供给用户使用。 一个典型的分布式数据一致性的解决方案,分布式应用程序可以基于它实现诸如数据发布/订阅、负载均衡、命名服务、分布式协调/通知、集群管理、Master 选举、分布式锁和分布式队列等功能。二、zookeeper 数据结构zookeeper 提供的名称空间非常类似于标准文件系统,key-value 的形式存储。名称 key 由斜线 / 分割的一系列路径元素,zookeeper 名称空间中的每个节点都是由一个路径标识。三、相关 CAP 理论CAP 理论指出对于一个分布式计算系统来说,不可能同时满足以下三点: 一致性:在分布式环境中,一致性是指数据在多个副本之间是否能够保持一致的特性,等同于所有节点访问同一份最新的数据副本。在一致性的需求下,当一个系统在数据一致的状态下执行更新操作后,应该保证系统的数据仍然处于一致的状态。 -可用性:每次请求都能获取到正确的响应,但是不保证获取的数据为最新数据。 -分区容错性:分布式系统在遇到任何网络分区故障的时候,仍然需要能够保证对外提供满足一致性和可用性的服务,除非是整个网络环境都发生了故障。 -一个分布式系统最多只能同时满足一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance)这三项中的两项。 在这三个基本需求中,最多只能同时满足其中的两项,P 是必须的,因此只能在 CP 和 AP 中选择,zookeeper 保证的是 CP,对比 spring cloud 系统中的注册中心 eruka 实现的是 AP。四、BASE 理论BASE 是 Basically Available(基本可用)、Soft-state(软状态) 和 Eventually Consistent(最终一致性) 三个短语的缩写。 - 基本可用:在分布式系统出现故障,允许损失部分可用性(服务降级、页面降级)。 - 软状态:允许分布式系统出现中间状态。而且中间状态不影响系统的可用性。这里的中间状态是指不同的 data replication(数据备份节点)之间的数据更新可以出现延时的最终一致性。 - 最终一致性:data replications 经过一段时间达到一致性。 BASE 理论是对 CAP 中的一致性和可用性进行一个权衡的结果,理论的核心思想就是:我们无法做到强一致,但每个应用都可以根据自身的业务特点,采用适当的方式来使系统达到最终一致性。五、官网zookeeper 官网:https://zookeeper.apache.org/
-
部署zabbix 一、规划与准备 1.1 准备一台部署主机系统:任意 Linux(推荐 Ubuntu 20.04+/Debian 11+/Rocky 8+)。 资源:最低 2 vCPU / 4GB RAM / 50GB 磁盘(随监控规模增长再加)。 已安装:Docker Engine + Docker Compose v2。 时间同步:ntp 或 chrony,保证时钟正确,否则趋势图会异常。1.2开放/规划端口Web:80/443(给 Zabbix 前端)。 服务器:10051/TCP(Zabbix Server 对外)。 Agent:10050/TCP(各主机上 agent 暴露,Server 来拉)。 vCenter/ESXi:443/TCP(Zabbix Server 访问 vCenter/ESXi API)。 K8s 节点:如果用 Agent 主动模式也只需 Server 的 10051 可达。1.3选择版本与时区建议用 Zabbix 7.0 LTS 镜像系列(稳定、支持期长)。 时区按你的习惯(你之前环境多用 Asia/Shanghai;若在韩区可用 Asia/Seoul)。二、用 Docker Compose 部署 Zabbix 2.1 目录与环境变量[root@vmpzax102 zabbix]# cat ./.env # 数据库 POSTGRES_USER=zabbix POSTGRES_PASSWORD=zabbixDB POSTGRES_DB=zabbix # 时区(Web 与 Server 分别使用) TZ=Asia/Shanghai PHP_TZ=Asia/Shanghai # Zabbix Server 基本调优(按规模可再改) ZBX_TIMEOUT=30 ZBX_CACHESIZE=256M ZBX_STARTVMWARECOLLECTORS=4 [root@vmpzax102 zabbix]# cat docker-compose.yml version: "3.9" services: postgres: image: postgres:15-alpine container_name: zbx-postgres restart: unless-stopped environment: POSTGRES_USER: ${POSTGRES_USER} POSTGRES_PASSWORD: ${POSTGRES_PASSWORD} POSTGRES_DB: ${POSTGRES_DB} TZ: ${TZ:-Asia/Shanghai} volumes: - ./postgres:/var/lib/postgresql/data:Z healthcheck: test: ["CMD-SHELL", "pg_isready -U ${POSTGRES_USER} -d ${POSTGRES_DB}"] interval: 10s timeout: 5s retries: 10 zabbix-server: image: zabbix/zabbix-server-pgsql:alpine-7.0-latest container_name: zbx-server restart: unless-stopped depends_on: postgres: condition: service_healthy ports: - "10051:10051" environment: DB_SERVER_HOST: postgres POSTGRES_USER: ${POSTGRES_USER} POSTGRES_PASSWORD: ${POSTGRES_PASSWORD} POSTGRES_DB: ${POSTGRES_DB} TZ: ${TZ:-Asia/Shanghai} # —— 关键:开启 VMware 采集器 —— ZBX_STARTVMWARECOLLECTORS: "2" # 至少 1;根据规模可调大 ZBX_VMWAREFREQUENCY: "60" # vSphere 清单/任务采集频率(秒) ZBX_VMWAREPERFFREQUENCY: "60" # 性能采样频率(秒) # 常用调优(可按需调整) ZBX_TIMEOUT: "30" ZBX_CACHESIZE: "256M" ZBX_SSLCALOCATION: /var/lib/zabbix/ssl/ssl_ca volumes: - ./alertscripts:/usr/lib/zabbix/alertscripts:Z - ./externalscripts:/usr/lib/zabbix/externalscripts:Z - ./enc:/var/lib/zabbix/enc:Z - ./export:/var/lib/zabbix/export:Z - ./modules:/var/lib/zabbix/modules:Z - ./ssh_keys:/var/lib/zabbix/ssh_keys:Z - ./snmptraps:/var/lib/zabbix/snmptraps:Z - /var/zabbix/ssl/ssl_ca:/var/lib/zabbix/ssl/ssl_ca:ro healthcheck: test: ["CMD-SHELL", "pgrep zabbix_server >/dev/null || exit 1"] interval: 10s timeout: 5s retries: 10 zabbix-web: image: zabbix/zabbix-web-nginx-pgsql:alpine-7.0-latest container_name: zbx-web restart: unless-stopped depends_on: postgres: condition: service_healthy zabbix-server: condition: service_started ports: - "80:8080" - "443:8443" environment: DB_SERVER_HOST: postgres POSTGRES_USER: ${POSTGRES_USER} POSTGRES_PASSWORD: ${POSTGRES_PASSWORD} POSTGRES_DB: ${POSTGRES_DB} ZBX_SERVER_HOST: zabbix-server PHP_TZ: ${PHP_TZ:-Asia/Shanghai} TZ: ${TZ:-Asia/Shanghai} # 如需自有证书,取消下面注释并替换为你的证书: # volumes: # - ./tls/host.crt:/etc/ssl/nginx/host.crt:Z # - ./tls/host.key:/etc/ssl/nginx/host.key:Z # 可选:本机自监控 Agent2 zabbix-agent2: image: zabbix/zabbix-agent2:alpine-7.0-latest container_name: zbx-agent2 restart: unless-stopped network_mode: host environment: ZBX_SERVER_HOST: "172.18.0.3,192.168.173.102" # 允许被动来源地址 ZBX_SERVER_ACTIVE: "192.168.173.102" # 主动上报目标(你的 Server 所在主机 IP) ZBX_HOSTNAME: "vmpzax102" TZ: ${TZ:-Asia/Shanghai} volumes: - /:/hostfs:ro,rslave - /var/run:/var/run - /sys:/sys - /proc:/proc - /dev:/dev #启动 docker compose pull docker compose up -d docker compose ps浏览器访问: http://<部署主机IP>/(或 https://<ip>/) 默认账户:Admin / 密码:zabbix(首次登录请立刻修改)三、给不同平台接入监控建议统一 “主动(active)模式” + 自动注册,省心可靠(特别是跨网段、云上主机)。3.1 Linux(CentOS/Ubuntu 等)安装 agent2# 1) 安装 Zabbix 7.0 源 rpm -Uvh https://repo.zabbix.com/zabbix/7.0/rhel/7/x86_64/zabbix-release-7.0-1.el7.noarch.rpm yum clean all # 2) 安装 agent2 yum install -y zabbix-agent2 # 3) 配置(/etc/zabbix/zabbix_agent2.conf) # 关键项示例: # Server=<Zabbix-Server-IP> # 被动模式需要;即允许谁来连 10050 # ServerActive=<Zabbix-Server-IP> # 主动模式 Server 地址(也可以写域名) # HostnameItem=system.hostname # HostMetadata=LINUX # 供自动注册规则识别 # TLSPSKIdentity/ TLSPSKFile(如需PSK加密) # 4) 启动 systemctl enable --now zabbix-agent2 # 确认 10050 端口监听 ss -lntp | grep 10050 #Ubuntu/Debian 类似:安装 zabbix-release .deb 后 apt install zabbix-agent2。3.2 Windows Server 安装 agent2方法 1(图形化):下载 zabbix_agent2.msi(7.0 对应版本) → 双击安装 Server:填写 Zabbix Server IP ServerActive:同上 Hostname:留空/默认(使用系统名) HostMetadata:填 WINDOWS方法 2(自动化,PowerShell): $ver = "7.0.0" # 按实际版本 $msi = "zabbix_agent2-$ver-windows-amd64-openssl.msi" $uri = "https://cdn.zabbix.com/zabbix/binaries/stable/7.0/$ver/$msi" # 示例 Invoke-WebRequest $uri -OutFile $msi Start-Process msiexec.exe -Wait -ArgumentList @( "/i", $msi, "SERVER=<Zabbix-Server-IP>", "SERVERACTIVE=<Zabbix-Server-IP>", "HOSTMETADATA=WINDOWS", "HOSTNAMEITEM=system.hostname", "/qn" ) Start-Service "Zabbix Agent 2" Set-Service "Zabbix Agent 2" -StartupType Automatic #Windows 防火墙若拦截 10050,放行即可;主动模式不要求外部能连 10050,但被动需要。3.3 ESXi / vCenter 监控(通过 VMware API)推荐对接 vCenter,一个入口监控所有 ESXi/VM:
-
rocky linux 9 安装 多主架构 一、固定IP地址#配置 sudo nmcli connection modify ens160 \ ipv4.method manual \ ipv4.addresses 192.168.30.50/24 \ ipv4.gateway 192.168.30.2 \ ipv4.dns "8.8.8.8,8.8.4.4" #更新配置 sudo nmcli connection down ens160 && sudo nmcli connection up ens160二、准备工作 2.0 修改主机名#每个节点对应一个 hostnamectl set-hostname k8s-01 hostnamectl set-hostname k8s-02 hostnamectl set-hostname k8s-03#提前配好vip ip 三个节点都要做 cat >>/etc/hosts <<'EOF' 192.168.30.50 k8s-01 192.168.30.51 k8s-02 192.168.30.52 k8s-03 192.168.30.58 k8s-vip EOF2.1 配置yum源#sudo mkdir /etc/yum.repos.d/backup #sudo mv /etc/yum.repos.d/*.repo /etc/yum.repos.d/backup/ 直接执行下面的 # 使用阿里云推荐的配置方法 sudo sed -e 's!^mirrorlist=!#mirrorlist=!g' \ -e 's!^#baseurl=http://dl.rockylinux.org/$contentdir!baseurl=https://mirrors.aliyun.com/rockylinux!g' \ -i /etc/yum.repos.d/Rocky-*.repo #清理并重建缓存 sudo dnf clean all sudo dnf makecache #测试更新 sudo dnf -y update sudo dnf -y install wget curl vim tar gzip2.2设置时区#查看当前时区设置 timedatectl #设置时区为中国时区(上海时间) sudo timedatectl set-timezone Asia/Shanghai2.3设置时间#安装并配置 Chrony(推荐) # RHEL/CentOS/Alma/Rocky sudo dnf -y install chrony || sudo yum -y install chrony sudo systemctl enable --now chronyd # 编辑配置文件 sudo vi /etc/chrony.conf #把默认的 pool/server 行注释掉(没外网也无用),然后加入(或确认存在)以下内容: # 把 30.50 作为“本地时间源”,无外部上游时自成一体 local stratum 10 # 允许本网段客户端访问 allow 192.168.30.0/24 # 绑定监听到这块网卡(可选,但建议写上) bindaddress 192.168.30.50 # 客户端第一次偏差大时允许快速步进校时 makestep 1 3 # 用系统时钟做源,且把系统时间同步到硬件时钟(断电后也较准) rtcsync #保存重启 sudo systemctl restart chronyd #防火墙放行 # firewalld(RHEL系) sudo firewall-cmd --add-service=ntp --permanent sudo firewall-cmd --reload #验证服务器状态 # 查看 chrony 源与自我状态 chronyc tracking # 查看已连接的客户端(执行一会儿后能看到) chronyc clients # 确认监听 123/udp sudo ss -lunp | grep :123# 客户端安装 # RHEL系 sudo dnf -y install chrony || sudo yum -y install chrony # Debian/Ubuntu sudo apt -y install chrony # 配置(RHEL: /etc/chrony.conf;Ubuntu/Debian: /etc/chrony/chrony.conf) # 注释掉原来的 pool/server 行,新增: server 192.168.30.50 iburst # 重启并查看 sudo systemctl restart chronyd chronyc sources -v chronyc tracking2.4关闭swap分区sudo swapoff -a sudo sed -ri '/\sswap\s/s/^#?/#/' /etc/fstab2.5关闭selinuxsudo systemctl disable --now firewalld #推荐:保持 Enforcing(Kubernetes + containerd 在 RHEL9 系已支持),同时安装策略包: sudo dnf -y install container-selinux getenforce # 看到 Enforcing 即可 #图省事(不太安全):设为 Permissive: sudo setenforce 0 sudo sed -i 's/^SELINUX=enforcing/SELINUX=permissive/' /etc/selinux/config2.6内核模块与 sysctl(所有节点)# 加载并持久化必须内核模块 cat <<'EOF' | sudo tee /etc/modules-load.d/k8s.conf overlay br_netfilter EOF sudo modprobe overlay sudo modprobe br_netfilter # 必备内核参数(转发与桥接) cat <<'EOF' | sudo tee /etc/sysctl.d/99-kubernetes-cri.conf net.bridge.bridge-nf-call-iptables = 1 net.bridge.bridge-nf-call-ip6tables = 1 net.ipv4.ip_forward = 1 EOF sudo sysctl --system #说明:RHEL9/ Rocky9 默认 cgroup v2,Kubernetes + containerd 完全支持,无需改动。2.7文件描述符(fd/ulimit)与进程数# 系统级最大打开文件数 cat > /etc/security/limits.d/k8s.conf <<EOF * soft nofile 65535 * hard nofile 131070 EOF ulimit -Sn ulimit -Hn2.8kube-proxy 的 IPVS 模式#安装 sudo dnf -y install ipset ipvsadm cat <<'EOF' | sudo tee /etc/modules-load.d/k8s.conf overlay br_netfilter # 如启用 IPVS,取消以下行的注释: ip_vs ip_vs_rr ip_vs_wrr ip_vs_sh nf_conntrack EOF # 立即加载 sudo modprobe overlay sudo modprobe br_netfilter # 如果要用 IPVS,再执行: for m in ip_vs ip_vs_rr ip_vs_wrr ip_vs_sh nf_conntrack; do sudo modprobe $m; done #验证模块 lsmod | egrep 'br_netfilter|ip_vs|nf_conntrack'三、安装containerd(所有k8s节点都要做) 3.1 使用阿里云的源sudo dnf config-manager --set-enabled powertools # Rocky Linux 8/9需启用PowerTools仓库 sudo dnf install -y yum-utils device-mapper-persistent-data lvm2 #1、卸载之前的 dnf remove docker docker-ce containerd docker-common docker-selinux docker-engine -y #2、准备repo sudo tee /etc/yum.repos.d/docker-ce.repo <<-'EOF' [docker-ce-stable] name=Docker CE Stable - AliOS baseurl=https://mirrors.aliyun.com/docker-ce/linux/centos/$releasever/$basearch/stable enabled=1 gpgcheck=1 gpgkey=https://mirrors.aliyun.com/docker-ce/linux/centos/gpg EOF # 3、安装 sudo dnf install -y containerd.io sudo dnf install containerd* -y3.2配置# 1、配置 mkdir -pv /etc/containerd containerd config default > /etc/containerd/config.toml #为containerd生成配置文件 #2、替换默认pause镜像地址:这一步非常非常非常非常重要 grep sandbox_image /etc/containerd/config.toml sudo sed -i 's|registry.k8s.io/pause:3.8|registry.cn-guangzhou.aliyuncs.com/xingcangku/registry.k8s.io-pause:3.8|g' /etc/containerd/config.toml grep sandbox_image /etc/containerd/config.toml #请务必确认新地址是可用的: sandbox_image = "registry.cn-guangzhou.aliyuncs.com/xingcangku/registry.k8s.io-pause:3.8" #3、配置systemd作为容器的cgroup driver grep SystemdCgroup /etc/containerd/config.toml sed -i 's/SystemdCgroup \= false/SystemdCgroup \= true/' /etc/containerd/config.toml grep SystemdCgroup /etc/containerd/config.toml # 4、配置加速器(必须配置,否则后续安装cni网络插件时无法从docker.io里下载镜像) #参考:https://github.com/containerd/containerd/blob/main/docs/cri/config.md#registry-configuration #添加 config_path="/etc/containerd/certs.d" sed -i 's/config_path\ =.*/config_path = \"\/etc\/containerd\/certs.d\"/g' /etc/containerd/config.tomlmkdir -p /etc/containerd/certs.d/docker.io cat>/etc/containerd/certs.d/docker.io/hosts.toml << EOF server ="https://docker.io" [host."https ://dockerproxy.com"] capabilities = ["pull","resolve"] [host."https://docker.m.daocloud.io"] capabilities = ["pull","resolve"] [host."https://docker.chenby.cn"] capabilities = ["pull","resolve"] [host."https://registry.docker-cn.com"] capabilities = ["pull","resolve" ] [host."http://hub-mirror.c.163.com"] capabilities = ["pull","resolve" ] EOF#5、配置containerd开机自启动 #5.1 启动containerd服务并配置开机自启动 systemctl daemon-reload && systemctl restart containerd systemctl enable --now containerd #5.2 查看containerd状态 systemctl status containerd #5.3查看containerd的版本 ctr version四、安装nginx+keepalived#安装与开启 dnf install -y nginx keepalived curl dnf install -y nginx-mod-stream systemctl enable nginx keepalived #配置 Nginx(两台 Master 都要配) #目标:在本机 0.0.0.0:16443 监听,转发到两个后端的 kube-apiserver(50:16443、51:16443) #编辑 /etc/nginx/nginx.conf(保留 http 段也没关系,关键是顶层加上 stream 段;Rocky9 的 nginx 支持动态模块): # /etc/nginx/nginx.conf user nginx; worker_processes auto; error_log /var/log/nginx/error.log; pid /run/nginx.pid; # 使用系统提供的动态模块配置(若已安装将自动加载 stream 模块) include /usr/share/nginx/modules/*.conf; events { worker_connections 10240; } # 四层转发到两台 apiserver stream { upstream k8s_apiserver { server 192.168.30.50:6443 max_fails=3 fail_timeout=10s; server 192.168.30.51:6443 max_fails=3 fail_timeout=10s; } server { listen 0.0.0.0:16443; proxy_connect_timeout 5s; proxy_timeout 30s; proxy_pass k8s_apiserver; } } http { # 这里保持nginx默认 http 配置即可,删与不删均可。 include /etc/nginx/mime.types; default_type application/octet-stream; sendfile on; keepalive_timeout 65; server { listen 81; return 200 "ok\n"; } } #配置 Keepalived(两台 Master) #创建健康检查脚本 /etc/keepalived/check_nginx_kube.sh: cat >/etc/keepalived/check_nginx_kube.sh <<'EOF' #!/usr/bin/env bash # 通过本地Nginx转发口探活K8s apiserver(无认证的 /readyz,HTTP 200 即通过) curl -fsSk --connect-timeout 2 https://127.0.0.1:16443/readyz >/dev/null EOF chmod +x /etc/keepalived/check_nginx_kube.sh #Master1(192.168.30.50) 的 /etc/keepalived/keepalived.conf: ! Configuration File for keepalived global_defs { router_id LVS_K8S_50 # vrrp_strict # 若使用部分虚拟化/容器网络会引发问题,可注释掉 } vrrp_script chk_nginx_kube { script "/etc/keepalived/check_nginx_kube.sh" interval 3 timeout 2 fall 2 rise 2 weight -20 } vrrp_instance VI_1 { state BACKUP interface ens160 # 改为你的网卡 virtual_router_id 58 # 1-255 任意一致值,这里取 58 priority 150 # Master1 高优先 advert_int 1 # 单播,避免二层组播受限环境(强烈推荐) unicast_src_ip 192.168.30.50 unicast_peer { 192.168.30.51 } authentication { auth_type PASS auth_pass 9c9c58 } virtual_ipaddress { 192.168.30.58/24 dev ens160 } track_script { chk_nginx_kube } } #Master2(192.168.30.151) 的 /etc/keepalived/keepalived.conf: ! Configuration File for keepalived global_defs { router_id LVS_K8S_51 # vrrp_strict } vrrp_script chk_nginx_kube { script "/etc/keepalived/check_nginx_kube.sh" interval 3 timeout 2 fall 2 rise 2 weight -20 } vrrp_instance VI_1 { state BACKUP interface ens160 virtual_router_id 58 priority 100 # 次优先 advert_int 1 unicast_src_ip 192.168.30.51 unicast_peer { 192.168.30.50 } authentication { auth_type PASS auth_pass 9c9c58 } virtual_ipaddress { 192.168.30.58/24 dev ens160 } track_script { chk_nginx_kube } } #启动 systemctl restart keepalived ip a | grep 192.168.30.58 #停掉 Master1 的 keepalived:systemctl stop keepalived,VIP 应在 Master2 出现,验证完再 systemctl start keepalived。五、安装k8s 5.1 准备k8s源# 创建repo文件 cat <<EOF | sudo tee /etc/yum.repos.d/kubernetes.repo [kubernetes] name=Kubernetes baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/ enabled=1 gpgcheck=1 repo_gpgcheck=1 gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg EOF sudo dnf makecache #参考:https://developer.aliyun.com/mirror/kubernetes/setenforce dnf install -y kubelet-1.27* kubeadm-1.27* kubectl-1.27* systemctl enable kubelet && systemctl start kubelet && systemctl status kubelet 安装锁定版本的插件 sudo dnf install -y dnf-plugin-versionlock 锁定版本不让后续更新sudo dnf versionlock add kubelet-1.27* kubeadm-1.27* kubectl-1.27* containerd.io [root@k8s-01 ~]# sudo dnf versionlock list Last metadata expiration check: 0:35:21 ago on Fri Aug 8 10:40:25 2025. kubelet-0:1.27.6-0.* kubeadm-0:1.27.6-0.* kubectl-0:1.27.6-0.* containerd.io-0:1.7.27-3.1.el9.* #sudo dnf update就会排除锁定的应用5.2 主节点操作(node节点不执行)[root@k8s-01 ~]# kubeadm config images list I0906 16:16:30.198629 49023 version.go:256] remote version is much newer: v1.34.0; falling back to: stable-1.27 registry.k8s.io/kube-apiserver:v1.27.16 registry.k8s.io/kube-controller-manager:v1.27.16 registry.k8s.io/kube-scheduler:v1.27.16 registry.k8s.io/kube-proxy:v1.27.16 registry.k8s.io/pause:3.9 registry.k8s.io/etcd:3.5.7-0 registry.k8s.io/coredns/coredns:v1.10.1 kubeadm config print init-defaults > kubeadm.yaml[root@k8s-01 ~]# cat kubeadm.yaml # kubeadm-config.yaml apiVersion: kubeadm.k8s.io/v1beta3 kind: InitConfiguration bootstrapTokens: - token: abcdef.0123456789abcdef ttl: 24h0m0s usages: ["signing","authentication"] groups: ["system:bootstrappers:kubeadm:default-node-token"] localAPIEndpoint: # 这里必须是你要执行 kubeadm init 的这台机器的真实IP(Master1) advertiseAddress: 192.168.30.50 bindPort: 6443 nodeRegistration: criSocket: unix:///run/containerd/containerd.sock imagePullPolicy: IfNotPresent # 不要在这里硬编码 name,默认会用主机的 hostname,避免复用此文件时出错 taints: null --- apiVersion: kubeadm.k8s.io/v1beta3 kind: ClusterConfiguration clusterName: kubernetes kubernetesVersion: v1.27.16 controlPlaneEndpoint: "192.168.30.58:16443" # 指向 Nginx+Keepalived 的 VIP:PORT certificatesDir: /etc/kubernetes/pki imageRepository: registry.cn-hangzhou.aliyuncs.com/google_containers networking: dnsDomain: cluster.local serviceSubnet: 10.96.0.0/12 podSubnet: 10.244.0.0/16 # 供 Calico 使用,此网段可保持不变 apiServer: timeoutForControlPlane: 4m0s certSANs: # 建议把 VIP、两台 Master 的 IP 和主机名都放进 SAN,避免证书不信任 - "192.168.30.58" # VIP - "192.168.30.50" - "192.168.30.51" - "k8s-01" # 如你的主机名不同,请改成实际 hostname - "k8s-02" - "127.0.0.1" - "localhost" - "kubernetes" - "kubernetes.default" - "kubernetes.default.svc" - "kubernetes.default.svc.cluster.local" controllerManager: {} scheduler: {} etcd: local: dataDir: /var/lib/etcd --- apiVersion: kubeproxy.config.k8s.io/v1alpha1 kind: KubeProxyConfiguration mode: "ipvs" --- apiVersion: kubelet.config.k8s.io/v1beta1 kind: KubeletConfiguration cgroupDriver: "systemd"root@k8s-01 ~]# kubeadm init --config kubeadm.yaml --upload-certs [init] Using Kubernetes version: v1.27.16 [preflight] Running pre-flight checks [preflight] Pulling images required for setting up a Kubernetes cluster [preflight] This might take a minute or two, depending on the speed of your internet connection [preflight] You can also perform this action in beforehand using 'kubeadm config images pull' W0906 17:26:53.821977 54526 checks.go:835] detected that the sandbox image "registry.cn-guangzhou.aliyuncs.com/xingcangku/registry.k8s.io-pause:3.8" of the container runtime is inconsistent with that used by kubeadm. It is recommended that using "registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.9" as the CRI sandbox image. [certs] Using certificateDir folder "/etc/kubernetes/pki" [certs] Generating "ca" certificate and key [certs] Generating "apiserver" certificate and key [certs] apiserver serving cert is signed for DNS names [k8s-01 k8s-02 kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local localhost] and IPs [10.96.0.1 192.168.30.50 192.168.30.58 192.168.30.51 127.0.0.1] [certs] Generating "apiserver-kubelet-client" certificate and key [certs] Generating "front-proxy-ca" certificate and key [certs] Generating "front-proxy-client" certificate and key [certs] Generating "etcd/ca" certificate and key [certs] Generating "etcd/server" certificate and key [certs] etcd/server serving cert is signed for DNS names [k8s-01 localhost] and IPs [192.168.30.50 127.0.0.1 ::1] [certs] Generating "etcd/peer" certificate and key [certs] etcd/peer serving cert is signed for DNS names [k8s-01 localhost] and IPs [192.168.30.50 127.0.0.1 ::1] [certs] Generating "etcd/healthcheck-client" certificate and key [certs] Generating "apiserver-etcd-client" certificate and key [certs] Generating "sa" key and public key [kubeconfig] Using kubeconfig folder "/etc/kubernetes" [kubeconfig] Writing "admin.conf" kubeconfig file [kubeconfig] Writing "kubelet.conf" kubeconfig file [kubeconfig] Writing "controller-manager.conf" kubeconfig file [kubeconfig] Writing "scheduler.conf" kubeconfig file [kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env" [kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml" [kubelet-start] Starting the kubelet [control-plane] Using manifest folder "/etc/kubernetes/manifests" [control-plane] Creating static Pod manifest for "kube-apiserver" [control-plane] Creating static Pod manifest for "kube-controller-manager" [control-plane] Creating static Pod manifest for "kube-scheduler" [etcd] Creating static Pod manifest for local etcd in "/etc/kubernetes/manifests" [wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory "/etc/kubernetes/manifests". This can take up to 4m0s [apiclient] All control plane components are healthy after 12.002658 seconds [upload-config] Storing the configuration used in ConfigMap "kubeadm-config" in the "kube-system" Namespace [kubelet] Creating a ConfigMap "kubelet-config" in namespace kube-system with the configuration for the kubelets in the cluster [upload-certs] Storing the certificates in Secret "kubeadm-certs" in the "kube-system" Namespace [upload-certs] Using certificate key: 0574b43d75ac9722533a3a5042cb86b97441b855371cb34e5fdd3c8733a39d8d [mark-control-plane] Marking the node k8s-01 as control-plane by adding the labels: [node-role.kubernetes.io/control-plane node.kubernetes.io/exclude-from-external-load-balancers] [mark-control-plane] Marking the node k8s-01 as control-plane by adding the taints [node-role.kubernetes.io/control-plane:NoSchedule] [bootstrap-token] Using token: abcdef.0123456789abcdef [bootstrap-token] Configuring bootstrap tokens, cluster-info ConfigMap, RBAC Roles [bootstrap-token] Configured RBAC rules to allow Node Bootstrap tokens to get nodes [bootstrap-token] Configured RBAC rules to allow Node Bootstrap tokens to post CSRs in order for nodes to get long term certificate credentials [bootstrap-token] Configured RBAC rules to allow the csrapprover controller automatically approve CSRs from a Node Bootstrap Token [bootstrap-token] Configured RBAC rules to allow certificate rotation for all node client certificates in the cluster [bootstrap-token] Creating the "cluster-info" ConfigMap in the "kube-public" namespace [kubelet-finalize] Updating "/etc/kubernetes/kubelet.conf" to point to a rotatable kubelet client certificate and key [addons] Applied essential addon: CoreDNS [addons] Applied essential addon: kube-proxy Your Kubernetes control-plane has initialized successfully! To start using your cluster, you need to run the following as a regular user: mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config Alternatively, if you are the root user, you can run: export KUBECONFIG=/etc/kubernetes/admin.conf You should now deploy a pod network to the cluster. Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at: https://kubernetes.io/docs/concepts/cluster-administration/addons/ You can now join any number of the control-plane node running the following command on each as root: kubeadm join 192.168.30.58:6443 --token abcdef.0123456789abcdef \ --discovery-token-ca-cert-hash sha256:26d30a8cbfabc6d8a5b3965b9577a3ce33b01c4958a3e19fd001f06a0f3cb019 \ --control-plane --certificate-key 0574b43d75ac9722533a3a5042cb86b97441b855371cb34e5fdd3c8733a39d8d Please note that the certificate-key gives access to cluster sensitive data, keep it secret! As a safeguard, uploaded-certs will be deleted in two hours; If necessary, you can use "kubeadm init phase upload-certs --upload-certs" to reload certs afterward. Then you can join any number of worker nodes by running the following on each as root: kubeadm join 192.168.30.58:6443 --token abcdef.0123456789abcdef \ --discovery-token-ca-cert-hash sha256:26d30a8cbfabc6d8a5b3965b9577a3ce33b01c4958a3e19fd001f06a0f3cb019 #如果出现失败的情况 kubeadm reset -f [root@k8s-01 ~]# kubeadm reset -f [preflight] Running pre-flight checks W0906 17:08:03.892290 53705 removeetcdmember.go:106] [reset] No kubeadm config, using etcd pod spec to get data directory [reset] Deleted contents of the etcd data directory: /var/lib/etcd [reset] Stopping the kubelet service [reset] Unmounting mounted directories in "/var/lib/kubelet" W0906 17:08:03.899240 53705 cleanupnode.go:134] [reset] Failed to evaluate the "/var/lib/kubelet" directory. Skipping its unmount and cleanup: lstat /var/lib/kubelet: no such file or directory [reset] Deleting contents of directories: [/etc/kubernetes/manifests /etc/kubernetes/pki] [reset] Deleting files: [/etc/kubernetes/admin.conf /etc/kubernetes/kubelet.conf /etc/kubernetes/bootstrap-kubelet.conf /etc/kubernetes/controller-manager.conf /etc/kubernetes/scheduler.conf] The reset process does not clean CNI configuration. To do so, you must remove /etc/cni/net.d The reset process does not reset or clean up iptables rules or IPVS tables. If you wish to reset iptables, you must do so manually by using the "iptables" command. If your cluster was setup to utilize IPVS, run ipvsadm --clear (or similar) to reset your systems IPVS tables. The reset process does not clean your kubeconfig files and you must remove them manually. Please, check the contents of the $HOME/.kube/config file. #还需要手动删除 rm -rf /$HOME/.kube/config systemctl restart containerd rm -rf ~/.kube /etc/kubernetes/pki/* /etc/kubernetes/manifests/*#安装 CNI #Flannel(简单) kubectl apply -f https://raw.githubusercontent.com/flannel-io/flannel/v0.25.5/Documentation/kube-flannel.yml #Calico(功能更全) kubectl apply -f https://raw.githubusercontent.com/projectcalico/calico/v3.27.3/manifests/calico.yaml [root@k8s-02 ~]# kubectl get pod -A NAMESPACE NAME READY STATUS RESTARTS AGE kube-system calico-kube-controllers-59765c79db-rvqm5 1/1 Running 0 8m3s kube-system calico-node-4jlgw 1/1 Running 0 8m3s kube-system calico-node-lvzgx 1/1 Running 0 8m3s kube-system calico-node-qdrmn 1/1 Running 0 8m3s kube-system coredns-65dcc469f7-gktmx 1/1 Running 0 51m kube-system coredns-65dcc469f7-wmppd 1/1 Running 0 51m kube-system etcd-k8s-01 1/1 Running 0 51m kube-system etcd-k8s-02 1/1 Running 0 20m kube-system kube-apiserver-k8s-01 1/1 Running 0 51m kube-system kube-apiserver-k8s-02 1/1 Running 0 19m kube-system kube-controller-manager-k8s-01 1/1 Running 1 (20m ago) 51m kube-system kube-controller-manager-k8s-02 1/1 Running 0 19m kube-system kube-proxy-k7z9v 1/1 Running 0 22m kube-system kube-proxy-sgrln 1/1 Running 0 51m kube-system kube-proxy-wpkjb 1/1 Running 0 20m kube-system kube-scheduler-k8s-01 1/1 Running 1 (19m ago) 51m kube-system kube-scheduler-k8s-02 1/1 Running 0 19m #测试切换 #在当前 VIP 所在主机执行: systemctl stop keepalived #观察另外一台是否接管 VIP: ip a | grep 192.168.30.58 #再次访问: 正常会返回ok curl -k https://192.168.30.58:6443/readyz #恢复 vip会自动漂移回来 systemctl start keepalived#kubectl 正常 [root@k8s-01 ~]# kubectl get cs 2>/dev/null || \ kubectl get --raw='/readyz?verbose' | head NAME STATUS MESSAGE ERROR scheduler Healthy ok controller-manager Healthy ok etcd-0 Healthy