搜索到
99
篇与
的结果
-
 问题 调用 grafana 接口失败 error trying to reach service: dial tcp 10.244.2.60:3000: i/o timeout① 背景(30 秒) “有一次我们在 Kubernetes 集群里部署监控体系(Prometheus + Grafana),Grafana Pod 本身是 Running 的,但从节点或者其他组件访问 Grafana 的 Pod IP 的时候一直超时,curl 会直接 i/o timeout,影响监控平台的接入和联调。” “表面看 Grafana 是正常的,但网络层面存在异常。”② 问题拆解与排查思路(1 分钟) “我当时按分层排查的思路来做,而不是直接改网络策略。” 1️⃣ 先排除应用问题 我先 kubectl exec 进 Grafana Pod,直接 curl 127.0.0.1:3000/api/health 返回 200,说明 Grafana 本身没问题,端口监听正常 👉 这一步可以明确:不是应用、不是容器启动问题。 2️⃣ 再定位是 Service 层还是 Pod 网络问题 我确认 Service / Endpoint 都指向正确的 Pod IP 但从节点直接 curl PodIP 仍然超时 在同节点起一个临时 curl Pod 访问 PodIP,也同样超时 👉 这一步可以确定: 不是宿主机路由问题,而是 Pod 网络路径被拦截。 3️⃣ 确认 CNI 和隧道是否正常 集群使用的是 Cilium + VXLAN 我抓包看到 8472/UDP 的 VXLAN 流量是存在的 说明 overlay 隧道本身工作正常,否则整个集群通信都会异常 👉 到这里,网络连通性问题基本被排除。③ 关键突破点(40 秒) “真正的突破点是在 Cilium 的可观测工具 上。” 我在节点上执行了: cilium monitor --type drop 发现每一次访问 Grafana 3000 端口的 TCP SYN 都被丢弃 丢包原因非常明确:Policy denied 源身份显示为 remote-node 或 host 👉 这一步明确告诉我: 不是网络问题,而是被 Cilium 的策略明确拒绝了。④ 根因分析(30 秒) “回头检查发现,Grafana 所在命名空间里存在默认的 NetworkPolicy,只允许 Prometheus Pod 访问 Grafana 的 3000 端口。” 节点 / 宿主机访问 Grafana 时: 在 Cilium 里会被标记为 host 或 remote-node 并不属于普通 Pod identity 所以即使我用 Kubernetes NetworkPolicy 加了 ipBlock,依然无法命中这类流量 👉 本质原因是: Cilium 是以 identity/entity 为核心做策略决策,而不是单纯基于 IP。⑤ 解决方案(30 秒) “最终我使用的是 CiliumNetworkPolicy,显式放行来自节点的流量。” 在策略里允许: fromEntities: host fromEntities: remote-node 只放行到 Grafana 的 3000/TCP 应用策略后,从节点 curl PodIP 立刻恢复正常。⑥ 总结与价值(20 秒) “这个问题让我印象很深的一点是: 在使用 Cilium 这类 eBPF CNI 时,排查网络问题一定要用它自己的观测工具,而不是只停留在 Kubernetes NetworkPolicy 的抽象层。” “后续我也把这个问题整理成了 SOP,明确: Pod→Pod Node→Pod Service→Pod 在 Cilium 下对应的 identity 和策略差异,避免再踩坑。”面试官常见追问 & 标准答法(加分项) ❓追问 1:为什么 ipBlock 不生效? 答: “因为在 Cilium 里,Node / Host 流量优先按 identity(host / remote-node)匹配策略,而不是单纯按源 IP。 NetworkPolicy 的 ipBlock 在这类流量场景下不会命中,所以需要用 CiliumNetworkPolicy 的 fromEntities。” ❓追问 2:为什么不用 NodePort / LoadBalancer? 答: “NodePort 确实能绕开 Pod 网络策略,但会引入额外暴露面,不符合最小权限原则。 这里的目标只是节点内部访问 Pod 服务,用 CNI 级别策略精确放行更安全、更可控。” ❓追问 3:如何避免以后再发生? 答: 明确区分 Pod 流量 vs Node/Host 流量 在启用 Cilium 的集群里: 默认 NetworkPolicy + 例外的 CiliumNetworkPolicy 遇到网络问题第一时间用 cilium monitor / hubble observe 定位丢包原因,而不是盲改规则 🧠 面试官听到的“隐藏信号” 你这段回答会传递出几个非常强的信号: 你理解 CNI 底层实现,不只是会写 YAML 你会用 可观测工具定位问题 你做的是 体系化排障,而不是拍脑袋改配置 你有 复盘和沉淀能力 如果你愿意,下一步我还能帮你: 把这个案例改成 简历上的一条高质量项目经历 或模拟一次面试官“深挖追问”的对话,帮你把回答打磨到非常顺 你这个案例,放在 K8s 运维 / 平台工程 / SRE 面试里,是妥妥的加分项。root@k8s-01:~# cat > /tmp/cnp-allow-grafana-3000-from-nodes.yaml <<'EOF' apiVersion: cilium.io/v2 kind: CiliumNetworkPolicy metadata: name: allow-grafana-3000-from-nodes namespace: kuboard spec: endpointSelector: matchLabels: app.kubernetes.io/name: grafana ingress: - fromEntities: - host - remote-node toPorts: - ports: - port: "3000" protocol: TCP EOF kubectl apply -f /tmp/cnp-allow-grafana-3000-from-nodes.yaml kubectl -n kuboard get cnp | grep allow-grafana-3000-from-nodes ciliumnetworkpolicy.cilium.io/allow-grafana-3000-from-nodes created allow-grafana-3000-from-nodes 0s True root@k8s-01:~# curl -sS -m 3 http://10.244.2.60:3000/api/health { "database": "ok", "version": "11.2.0", "commit": "2a88694fd3ced0335bf3726cc5d0adc2d1858855" }root@k8s-01:~# 可以了 你现在是一个资深的k8s运维工程师 你帮我详细复盘分析之前的上下文 然后总结根因是什么?怎么解决的?为什么会出现这种情况 然后我想把这个问题也在面试上比如面试官问我 工作当中遇到了什么问题 可以说这个 我是怎么遇到这个问题的 过程尝试了用什么方法解决 然后最后怎么找到问题的 怎么解决的 下面我按“资深 K8s 运维复盘”的方式,把你这次 Grafana Pod IP 不通的问题完整复盘一遍:现象 → 排查路径 → 关键证据 → 根因 → 解决方案 → 为什么会这样。最后再给你一段面试可直接复述的 STAR/故事版本。 1)现象是什么 Pod 里 Grafana 本身是好的: kubectl exec grafana -- curl 127.0.0.1:3000/api/health 返回 OK 日志正常、监听正常(Grafana 启动成功) 但是从 宿主机 / 节点 访问 Pod IP 超时: curl http://10.244.2.60:3000/api/health → i/o timeout 从 同节点的测试 Pod 访问 Pod IP 也超时: 你在 k8s-01 强制调度了 curlimages/curl 去 curl PodIP,仍然 timeout 这说明:不是“宿主机路由不通”,而是“到 Pod 的流量在某处被拦截/丢弃” 2)你做了哪些正确的排查动作(过程复盘) A. 先确认应用是否健康(排除应用问题) 你先在 grafana 容器内 curl 自己: 容器内 OK → Grafana 服务与端口没问题 这一步很关键:把“应用/容器问题”先排掉。 B. 再验证网络路径(区分 host、pod、service) kubectl get svc/ep 确认 endpoint 就是 10.244.2.60:3000 curl PodIP 超时,说明不是 Service 负载均衡层的问题,而是到 endpoint 的流量被拦截 C. 检查 CNI 模式与隧道 你确认了 Cilium 配置: routing-mode: tunnel tunnel-protocol: vxlan 并且抓包能看到 8472/UDP 的 VXLAN 流量 进出(说明隧道本身在工作) 这一点也非常关键:overlay 通道是通的,否则集群内大量 Pod 通信都会异常。 D. 最关键的一步:用 Cilium 观测“丢包原因” 你执行: cilium monitor --type drop 立刻得到核心证据: xx drop (Policy denied) ... identity 6820->29952: 10.244.0.206 -> 10.244.2.60:3000 tcp SYN 以及后面: xx drop (Policy denied) ... identity remote-node->29952: 10.244.0.18 -> 10.244.2.60:3000 tcp SYN 这两条信息极其重要,等价于告诉你: 不是路由问题 不是端口没监听 是 Cilium 的策略(Policy)明确拒绝了 SYN 到这一步,根因已经锁定在 NetworkPolicy / CiliumPolicy 方向。 3)根因是什么(总结一句话版) Grafana 所在命名空间存在默认更严格的 NetworkPolicy(只允许 Prometheus Pod 访问 Grafana:3000),而节点/宿主机流量在 Cilium 里被标记成 remote-node/host 身份,不会被普通 K8s NetworkPolicy 的 ipBlock 命中,最终被 Cilium 以 Policy denied 丢弃。 再拆开说得更专业一点: 你原来的 NetworkPolicy(kuboard/grafana)是这样: ingress: - from: - podSelector: matchLabels: app.kubernetes.io/name: prometheus ports: - port: 3000 含义是: 只允许 prometheus 的 Pod 去访问 grafana 的 3000 其他来源(包括你从节点直接 curl PodIP)默认拒绝 为什么你加了 K8s NetworkPolicy(ipBlock)也没效果? 因为你的访问路径是“节点/宿主机 → Pod”: 从节点发起的流量到了 Cilium,会以 entity identity 来归类: host(本节点宿主机) remote-node(其他节点过来的 node traffic) 这类流量不是普通 Pod identity,很多情况下也不是单纯按源 IP去匹配 NetworkPolicy 的 ipBlock(尤其在 Cilium 的实现/模式下,优先按 identity 进行策略决策)。 所以你看到的现象就是: 你用 ipBlock: 192.168.1.0/24 放行 —— 依然被 remote-node identity 拒绝 你用 ipBlock: 10.244.0.0/16 放行 —— 依然被 remote-node identity 拒绝 而 cilium monitor 也明确显示拒绝原因是:Policy denied + identity remote-node->... 4)怎么解决的(你最终的正确做法) 你最终用了 CiliumNetworkPolicy: apiVersion: cilium.io/v2 kind: CiliumNetworkPolicy spec: endpointSelector: matchLabels: app.kubernetes.io/name: grafana ingress: - fromEntities: - host - remote-node toPorts: - ports: - port: "3000" protocol: TCP 这条规则的效果是: 明确放行 Cilium 的 entity host:本机宿主机进来的流量 remote-node:其他节点过来的 node 流量 只放行到 grafana pod 的 3000/TCP 所以你立刻在 k8s-01 上 curl PodIP 成功 5)为什么会出现这种情况(更“体系化”的解释) 1)装监控栈/平台时经常自带 NetworkPolicy 很多 kube-prometheus-stack / 平台化套件会默认创建 NetworkPolicy,实现“默认拒绝 + 白名单放行”,比如: Prometheus 可 scrape 其他来源默认不允许访问 UI/端口 这属于“安全默认值”,但会让排障时出现“明明 Pod Running,却访问超时”。 2)Cilium 对 Node/Host 流量有自己的 identity 体系 Cilium 的策略引擎不是只看 IP,而是以 identity/entity 为第一等公民: Pod 有 identity(基于 labels) Node/Host/Remote-node 是 entity 所以要放通 node→pod,最稳的是用 fromEntities: host/remote-node 这也是你最终方案成功的根本原因。 3)“Pod->Pod 通,Node->Pod 不通”是典型特征 因为: Pod→Pod 可能被某些 policy 放行了(或在同 namespace 里满足 selector) Node→Pod 不属于 podSelector 能匹配的对象,常被默认 deny 6)面试:如何把这件事讲成一个漂亮的“排障故事” 下面给你一个可直接背的版本(STAR + 技术细节),你按自己实际环境改两句就能用。 面试复述版本(建议 2~3 分钟) 背景(S) “我们在 K8s 集群里部署监控(Grafana/Prometheus),Grafana Pod Running,但业务方/运维侧从节点访问 Grafana API 一直 i/o timeout,影响监控平台接入和联调。” 任务(T) “我需要快速确认是应用问题、服务暴露问题还是集群网络策略问题,并给出可控的修复方案。” 行动(A) 先排除应用故障:进入 Grafana Pod 内部 curl 127.0.0.1:3000/api/health,确认服务健康、端口正常监听。 定位网络层级:从节点 curl PodIP 超时,同时在同节点跑一个临时 curl Pod 访问 PodIP 也超时,说明不是宿主机网络工具问题,而是集群网络路径被拦。 检查 CNI 与隧道:确认集群使用 Cilium,VXLAN 隧道 8472/UDP 有流量,说明 overlay 本身工作正常。 用可观测手段找“丢包理由”:运行 cilium monitor --type drop,发现对 Grafana:3000 的 SYN 被明确标记为 Policy denied,源身份显示为 remote-node/host。 回查 NetworkPolicy:发现 Grafana 命名空间有默认 NetworkPolicy,只允许 Prometheus Pod 访问 Grafana 3000,节点/宿主机流量不在白名单内,因此被 Cilium 拒绝。 修复策略:使用 CiliumNetworkPolicy 放行 fromEntities: host, remote-node 到 Grafana 的 3000/TCP,修复后节点 curl PodIP 立刻恢复。 结果(R) “Grafana API 访问恢复,监控平台联调继续推进。过程中我把排查步骤固化成 SOP:先应用健康检查→再分层定位→最后用 CNI 可观测工具确认策略/丢包原因,避免盲目改防火墙或路由。” 补充亮点(技术总结) “这类问题的关键点在于:Cilium 以 identity/entity 为核心做策略决策,Node/Host 流量常显示为 remote-node/host,单纯用 K8s NetworkPolicy 的 ipBlock 不一定能匹配到,需要用 CiliumNetworkPolicy 的 fromEntities 精准放行。”你是一个资深的k8s云原生运维工程师 你觉得碰到的这个问题有深度吗? 有,而且深度不在“Grafana 访问不通”这件事本身,而在你最后定位到的点:Cilium(eBPF)语义下,Host/Node 流量与 Pod 流量的身份模型差异,这已经超出“会用 K8s”的层级了。 我用面试官视角给你拆一下它为什么算“有深度”。 为什么这个问题有深度 1) 不是“网络不通”,是“策略语义不一致” 你一开始看到的是 timeout,很容易被带偏去查: VXLAN 8472/UDP、防火墙、路由、MTU、kube-proxy、Service/Endpoint 但最终根因是: NetworkPolicy 只放了 Prometheus 节点访问在 Cilium 里变成 host/remote-node identity 所以被 Policy denied 掉了 这属于 “抽象层(K8s NP) vs 实现层(Cilium identity/entity)”的差异问题,很典型也很难踩得准。 2) 你用的是“正确的高级排障工具链” 真正有经验的人会很快转向: cilium monitor --type drop / hubble 而不是一直“猜”。 你抓到的那句: drop (Policy denied) ... identity remote-node->... tcp SYN 这就是一锤定音的证据链。很多人排障卡住就是因为拿不到“谁丢的、为什么丢”。 3) 这是“集群行为”层面的知识点,不是某个组件 bug 你解决的不是 Grafana,也不是 curl,而是: CNI datapath identity-based enforcement node/host traffic classification NetworkPolicy 与 CiliumNetworkPolicy 的边界 这类问题在生产里经常发生在: metrics/health check 从节点探测 Pod ingress controller / node-local agent 访问业务 Pod 节点上跑的守护进程(daemonset 外部探测)访问 Pod 属于“平台层运维”常见痛点。 面试视角:它值不值得讲? 值得,尤其适合这些岗位: Kubernetes 运维 / 平台工程 / 云原生 SRE 网络/安全/可观测性方向 用 Cilium、Calico、Istio 的团队 但要注意一点: 你讲的重点一定要是“如何定位到 Policy denied + identity”,而不是“我改了很多 yaml”。 这题在“深度等级”大概在哪? 我会给它一个比较客观的分级: 初级:只会说“加个 NetworkPolicy 放行” 中级:知道分层排查(Pod 内 curl、Service、路由) 高级:能用 Cilium/Hubble 看到 Policy denied 并解释 host/remote-node identity 更高级:能进一步讲“为什么 ipBlock 不命中、为什么需要 fromEntities、如何标准化策略/避免误伤” 你这次已经到 高级门槛了。 如果你愿意,我还可以帮你把它再“拔高一档”——补上两句很能镇住面试官的话,比如: “我们在 Cilium 下把 Node->Pod 探测流量单独建了 fromEntities: host/remote-node 的 allowlist,避免跟业务 NP 混在一起。” “排查网络我会先看 datapath drop reason,避免在 overlay、iptables、policy 之间盲猜。” 你想把这题定位成你“最有含金量的一个案例”吗?我可以顺手帮你润色成简历 bullet。
问题 调用 grafana 接口失败 error trying to reach service: dial tcp 10.244.2.60:3000: i/o timeout① 背景(30 秒) “有一次我们在 Kubernetes 集群里部署监控体系(Prometheus + Grafana),Grafana Pod 本身是 Running 的,但从节点或者其他组件访问 Grafana 的 Pod IP 的时候一直超时,curl 会直接 i/o timeout,影响监控平台的接入和联调。” “表面看 Grafana 是正常的,但网络层面存在异常。”② 问题拆解与排查思路(1 分钟) “我当时按分层排查的思路来做,而不是直接改网络策略。” 1️⃣ 先排除应用问题 我先 kubectl exec 进 Grafana Pod,直接 curl 127.0.0.1:3000/api/health 返回 200,说明 Grafana 本身没问题,端口监听正常 👉 这一步可以明确:不是应用、不是容器启动问题。 2️⃣ 再定位是 Service 层还是 Pod 网络问题 我确认 Service / Endpoint 都指向正确的 Pod IP 但从节点直接 curl PodIP 仍然超时 在同节点起一个临时 curl Pod 访问 PodIP,也同样超时 👉 这一步可以确定: 不是宿主机路由问题,而是 Pod 网络路径被拦截。 3️⃣ 确认 CNI 和隧道是否正常 集群使用的是 Cilium + VXLAN 我抓包看到 8472/UDP 的 VXLAN 流量是存在的 说明 overlay 隧道本身工作正常,否则整个集群通信都会异常 👉 到这里,网络连通性问题基本被排除。③ 关键突破点(40 秒) “真正的突破点是在 Cilium 的可观测工具 上。” 我在节点上执行了: cilium monitor --type drop 发现每一次访问 Grafana 3000 端口的 TCP SYN 都被丢弃 丢包原因非常明确:Policy denied 源身份显示为 remote-node 或 host 👉 这一步明确告诉我: 不是网络问题,而是被 Cilium 的策略明确拒绝了。④ 根因分析(30 秒) “回头检查发现,Grafana 所在命名空间里存在默认的 NetworkPolicy,只允许 Prometheus Pod 访问 Grafana 的 3000 端口。” 节点 / 宿主机访问 Grafana 时: 在 Cilium 里会被标记为 host 或 remote-node 并不属于普通 Pod identity 所以即使我用 Kubernetes NetworkPolicy 加了 ipBlock,依然无法命中这类流量 👉 本质原因是: Cilium 是以 identity/entity 为核心做策略决策,而不是单纯基于 IP。⑤ 解决方案(30 秒) “最终我使用的是 CiliumNetworkPolicy,显式放行来自节点的流量。” 在策略里允许: fromEntities: host fromEntities: remote-node 只放行到 Grafana 的 3000/TCP 应用策略后,从节点 curl PodIP 立刻恢复正常。⑥ 总结与价值(20 秒) “这个问题让我印象很深的一点是: 在使用 Cilium 这类 eBPF CNI 时,排查网络问题一定要用它自己的观测工具,而不是只停留在 Kubernetes NetworkPolicy 的抽象层。” “后续我也把这个问题整理成了 SOP,明确: Pod→Pod Node→Pod Service→Pod 在 Cilium 下对应的 identity 和策略差异,避免再踩坑。”面试官常见追问 & 标准答法(加分项) ❓追问 1:为什么 ipBlock 不生效? 答: “因为在 Cilium 里,Node / Host 流量优先按 identity(host / remote-node)匹配策略,而不是单纯按源 IP。 NetworkPolicy 的 ipBlock 在这类流量场景下不会命中,所以需要用 CiliumNetworkPolicy 的 fromEntities。” ❓追问 2:为什么不用 NodePort / LoadBalancer? 答: “NodePort 确实能绕开 Pod 网络策略,但会引入额外暴露面,不符合最小权限原则。 这里的目标只是节点内部访问 Pod 服务,用 CNI 级别策略精确放行更安全、更可控。” ❓追问 3:如何避免以后再发生? 答: 明确区分 Pod 流量 vs Node/Host 流量 在启用 Cilium 的集群里: 默认 NetworkPolicy + 例外的 CiliumNetworkPolicy 遇到网络问题第一时间用 cilium monitor / hubble observe 定位丢包原因,而不是盲改规则 🧠 面试官听到的“隐藏信号” 你这段回答会传递出几个非常强的信号: 你理解 CNI 底层实现,不只是会写 YAML 你会用 可观测工具定位问题 你做的是 体系化排障,而不是拍脑袋改配置 你有 复盘和沉淀能力 如果你愿意,下一步我还能帮你: 把这个案例改成 简历上的一条高质量项目经历 或模拟一次面试官“深挖追问”的对话,帮你把回答打磨到非常顺 你这个案例,放在 K8s 运维 / 平台工程 / SRE 面试里,是妥妥的加分项。root@k8s-01:~# cat > /tmp/cnp-allow-grafana-3000-from-nodes.yaml <<'EOF' apiVersion: cilium.io/v2 kind: CiliumNetworkPolicy metadata: name: allow-grafana-3000-from-nodes namespace: kuboard spec: endpointSelector: matchLabels: app.kubernetes.io/name: grafana ingress: - fromEntities: - host - remote-node toPorts: - ports: - port: "3000" protocol: TCP EOF kubectl apply -f /tmp/cnp-allow-grafana-3000-from-nodes.yaml kubectl -n kuboard get cnp | grep allow-grafana-3000-from-nodes ciliumnetworkpolicy.cilium.io/allow-grafana-3000-from-nodes created allow-grafana-3000-from-nodes 0s True root@k8s-01:~# curl -sS -m 3 http://10.244.2.60:3000/api/health { "database": "ok", "version": "11.2.0", "commit": "2a88694fd3ced0335bf3726cc5d0adc2d1858855" }root@k8s-01:~# 可以了 你现在是一个资深的k8s运维工程师 你帮我详细复盘分析之前的上下文 然后总结根因是什么?怎么解决的?为什么会出现这种情况 然后我想把这个问题也在面试上比如面试官问我 工作当中遇到了什么问题 可以说这个 我是怎么遇到这个问题的 过程尝试了用什么方法解决 然后最后怎么找到问题的 怎么解决的 下面我按“资深 K8s 运维复盘”的方式,把你这次 Grafana Pod IP 不通的问题完整复盘一遍:现象 → 排查路径 → 关键证据 → 根因 → 解决方案 → 为什么会这样。最后再给你一段面试可直接复述的 STAR/故事版本。 1)现象是什么 Pod 里 Grafana 本身是好的: kubectl exec grafana -- curl 127.0.0.1:3000/api/health 返回 OK 日志正常、监听正常(Grafana 启动成功) 但是从 宿主机 / 节点 访问 Pod IP 超时: curl http://10.244.2.60:3000/api/health → i/o timeout 从 同节点的测试 Pod 访问 Pod IP 也超时: 你在 k8s-01 强制调度了 curlimages/curl 去 curl PodIP,仍然 timeout 这说明:不是“宿主机路由不通”,而是“到 Pod 的流量在某处被拦截/丢弃” 2)你做了哪些正确的排查动作(过程复盘) A. 先确认应用是否健康(排除应用问题) 你先在 grafana 容器内 curl 自己: 容器内 OK → Grafana 服务与端口没问题 这一步很关键:把“应用/容器问题”先排掉。 B. 再验证网络路径(区分 host、pod、service) kubectl get svc/ep 确认 endpoint 就是 10.244.2.60:3000 curl PodIP 超时,说明不是 Service 负载均衡层的问题,而是到 endpoint 的流量被拦截 C. 检查 CNI 模式与隧道 你确认了 Cilium 配置: routing-mode: tunnel tunnel-protocol: vxlan 并且抓包能看到 8472/UDP 的 VXLAN 流量 进出(说明隧道本身在工作) 这一点也非常关键:overlay 通道是通的,否则集群内大量 Pod 通信都会异常。 D. 最关键的一步:用 Cilium 观测“丢包原因” 你执行: cilium monitor --type drop 立刻得到核心证据: xx drop (Policy denied) ... identity 6820->29952: 10.244.0.206 -> 10.244.2.60:3000 tcp SYN 以及后面: xx drop (Policy denied) ... identity remote-node->29952: 10.244.0.18 -> 10.244.2.60:3000 tcp SYN 这两条信息极其重要,等价于告诉你: 不是路由问题 不是端口没监听 是 Cilium 的策略(Policy)明确拒绝了 SYN 到这一步,根因已经锁定在 NetworkPolicy / CiliumPolicy 方向。 3)根因是什么(总结一句话版) Grafana 所在命名空间存在默认更严格的 NetworkPolicy(只允许 Prometheus Pod 访问 Grafana:3000),而节点/宿主机流量在 Cilium 里被标记成 remote-node/host 身份,不会被普通 K8s NetworkPolicy 的 ipBlock 命中,最终被 Cilium 以 Policy denied 丢弃。 再拆开说得更专业一点: 你原来的 NetworkPolicy(kuboard/grafana)是这样: ingress: - from: - podSelector: matchLabels: app.kubernetes.io/name: prometheus ports: - port: 3000 含义是: 只允许 prometheus 的 Pod 去访问 grafana 的 3000 其他来源(包括你从节点直接 curl PodIP)默认拒绝 为什么你加了 K8s NetworkPolicy(ipBlock)也没效果? 因为你的访问路径是“节点/宿主机 → Pod”: 从节点发起的流量到了 Cilium,会以 entity identity 来归类: host(本节点宿主机) remote-node(其他节点过来的 node traffic) 这类流量不是普通 Pod identity,很多情况下也不是单纯按源 IP去匹配 NetworkPolicy 的 ipBlock(尤其在 Cilium 的实现/模式下,优先按 identity 进行策略决策)。 所以你看到的现象就是: 你用 ipBlock: 192.168.1.0/24 放行 —— 依然被 remote-node identity 拒绝 你用 ipBlock: 10.244.0.0/16 放行 —— 依然被 remote-node identity 拒绝 而 cilium monitor 也明确显示拒绝原因是:Policy denied + identity remote-node->... 4)怎么解决的(你最终的正确做法) 你最终用了 CiliumNetworkPolicy: apiVersion: cilium.io/v2 kind: CiliumNetworkPolicy spec: endpointSelector: matchLabels: app.kubernetes.io/name: grafana ingress: - fromEntities: - host - remote-node toPorts: - ports: - port: "3000" protocol: TCP 这条规则的效果是: 明确放行 Cilium 的 entity host:本机宿主机进来的流量 remote-node:其他节点过来的 node 流量 只放行到 grafana pod 的 3000/TCP 所以你立刻在 k8s-01 上 curl PodIP 成功 5)为什么会出现这种情况(更“体系化”的解释) 1)装监控栈/平台时经常自带 NetworkPolicy 很多 kube-prometheus-stack / 平台化套件会默认创建 NetworkPolicy,实现“默认拒绝 + 白名单放行”,比如: Prometheus 可 scrape 其他来源默认不允许访问 UI/端口 这属于“安全默认值”,但会让排障时出现“明明 Pod Running,却访问超时”。 2)Cilium 对 Node/Host 流量有自己的 identity 体系 Cilium 的策略引擎不是只看 IP,而是以 identity/entity 为第一等公民: Pod 有 identity(基于 labels) Node/Host/Remote-node 是 entity 所以要放通 node→pod,最稳的是用 fromEntities: host/remote-node 这也是你最终方案成功的根本原因。 3)“Pod->Pod 通,Node->Pod 不通”是典型特征 因为: Pod→Pod 可能被某些 policy 放行了(或在同 namespace 里满足 selector) Node→Pod 不属于 podSelector 能匹配的对象,常被默认 deny 6)面试:如何把这件事讲成一个漂亮的“排障故事” 下面给你一个可直接背的版本(STAR + 技术细节),你按自己实际环境改两句就能用。 面试复述版本(建议 2~3 分钟) 背景(S) “我们在 K8s 集群里部署监控(Grafana/Prometheus),Grafana Pod Running,但业务方/运维侧从节点访问 Grafana API 一直 i/o timeout,影响监控平台接入和联调。” 任务(T) “我需要快速确认是应用问题、服务暴露问题还是集群网络策略问题,并给出可控的修复方案。” 行动(A) 先排除应用故障:进入 Grafana Pod 内部 curl 127.0.0.1:3000/api/health,确认服务健康、端口正常监听。 定位网络层级:从节点 curl PodIP 超时,同时在同节点跑一个临时 curl Pod 访问 PodIP 也超时,说明不是宿主机网络工具问题,而是集群网络路径被拦。 检查 CNI 与隧道:确认集群使用 Cilium,VXLAN 隧道 8472/UDP 有流量,说明 overlay 本身工作正常。 用可观测手段找“丢包理由”:运行 cilium monitor --type drop,发现对 Grafana:3000 的 SYN 被明确标记为 Policy denied,源身份显示为 remote-node/host。 回查 NetworkPolicy:发现 Grafana 命名空间有默认 NetworkPolicy,只允许 Prometheus Pod 访问 Grafana 3000,节点/宿主机流量不在白名单内,因此被 Cilium 拒绝。 修复策略:使用 CiliumNetworkPolicy 放行 fromEntities: host, remote-node 到 Grafana 的 3000/TCP,修复后节点 curl PodIP 立刻恢复。 结果(R) “Grafana API 访问恢复,监控平台联调继续推进。过程中我把排查步骤固化成 SOP:先应用健康检查→再分层定位→最后用 CNI 可观测工具确认策略/丢包原因,避免盲目改防火墙或路由。” 补充亮点(技术总结) “这类问题的关键点在于:Cilium 以 identity/entity 为核心做策略决策,Node/Host 流量常显示为 remote-node/host,单纯用 K8s NetworkPolicy 的 ipBlock 不一定能匹配到,需要用 CiliumNetworkPolicy 的 fromEntities 精准放行。”你是一个资深的k8s云原生运维工程师 你觉得碰到的这个问题有深度吗? 有,而且深度不在“Grafana 访问不通”这件事本身,而在你最后定位到的点:Cilium(eBPF)语义下,Host/Node 流量与 Pod 流量的身份模型差异,这已经超出“会用 K8s”的层级了。 我用面试官视角给你拆一下它为什么算“有深度”。 为什么这个问题有深度 1) 不是“网络不通”,是“策略语义不一致” 你一开始看到的是 timeout,很容易被带偏去查: VXLAN 8472/UDP、防火墙、路由、MTU、kube-proxy、Service/Endpoint 但最终根因是: NetworkPolicy 只放了 Prometheus 节点访问在 Cilium 里变成 host/remote-node identity 所以被 Policy denied 掉了 这属于 “抽象层(K8s NP) vs 实现层(Cilium identity/entity)”的差异问题,很典型也很难踩得准。 2) 你用的是“正确的高级排障工具链” 真正有经验的人会很快转向: cilium monitor --type drop / hubble 而不是一直“猜”。 你抓到的那句: drop (Policy denied) ... identity remote-node->... tcp SYN 这就是一锤定音的证据链。很多人排障卡住就是因为拿不到“谁丢的、为什么丢”。 3) 这是“集群行为”层面的知识点,不是某个组件 bug 你解决的不是 Grafana,也不是 curl,而是: CNI datapath identity-based enforcement node/host traffic classification NetworkPolicy 与 CiliumNetworkPolicy 的边界 这类问题在生产里经常发生在: metrics/health check 从节点探测 Pod ingress controller / node-local agent 访问业务 Pod 节点上跑的守护进程(daemonset 外部探测)访问 Pod 属于“平台层运维”常见痛点。 面试视角:它值不值得讲? 值得,尤其适合这些岗位: Kubernetes 运维 / 平台工程 / 云原生 SRE 网络/安全/可观测性方向 用 Cilium、Calico、Istio 的团队 但要注意一点: 你讲的重点一定要是“如何定位到 Policy denied + identity”,而不是“我改了很多 yaml”。 这题在“深度等级”大概在哪? 我会给它一个比较客观的分级: 初级:只会说“加个 NetworkPolicy 放行” 中级:知道分层排查(Pod 内 curl、Service、路由) 高级:能用 Cilium/Hubble 看到 Policy denied 并解释 host/remote-node identity 更高级:能进一步讲“为什么 ipBlock 不命中、为什么需要 fromEntities、如何标准化策略/避免误伤” 你这次已经到 高级门槛了。 如果你愿意,我还可以帮你把它再“拔高一档”——补上两句很能镇住面试官的话,比如: “我们在 Cilium 下把 Node->Pod 探测流量单独建了 fromEntities: host/remote-node 的 allowlist,避免跟业务 NP 混在一起。” “排查网络我会先看 datapath drop reason,避免在 overlay、iptables、policy 之间盲猜。” 你想把这题定位成你“最有含金量的一个案例”吗?我可以顺手帮你润色成简历 bullet。 -
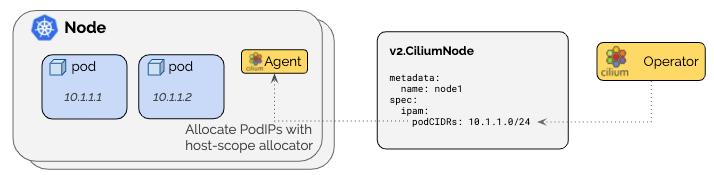
cilium部署 一、cilium介绍Cilium 本质上是一个 Kubernetes 的网络与安全组件(通常以 CNI 插件的身份安装),它用 eBPF 在 Linux 内核里实现:Pod/Service 的转发、网络策略(NetworkPolicy)、可观测性(流量可视化/追踪)、负载均衡,甚至部分服务网格能力。 可以把它理解成:“把 Kubernetes 网络、负载均衡和安全策略,尽量下沉到内核里做”,相比传统 iptables 方案更高性能、更可观测、策略能力更强。二、cilium是什么在 K8s 里,想让 Pod 能互通、能访问 Service、能做 NetworkPolicy,需要一个网络方案。Cilium 通常承担这些职责: 1. CNI(容器网络接口):给 Pod 分配 IP、配置路由/隧道/网卡,把 Pod 接入集群网络 2. Service 负载均衡实现:让访问 ClusterIP/NodePort/LoadBalancer 服务能正确转发到后端 Pod 3. 网络安全策略:实现 Kubernetes NetworkPolicy,甚至更强的 L3/L4/L7(HTTP/gRPC/DNS)策略 4. 网络可观测性:看到“谁在跟谁说话、延迟多少、丢包在哪里、命中了哪些策略” 5. (可选)替代 kube-proxy:用 eBPF 实现 Service 转发(kube-proxy replacement)三、cilium有什么用(解决了哪些痛点)A. 更快、更稳的转发与负载均衡 传统 kube-proxy 依赖 iptables/ipvs,规则多了会膨胀、调试困难。Cilium 用 eBPF 做转发和 LB: 1. 内核态快速转发(少走用户态/少遍历规则) 2. 大规模 Service/Endpoint 场景下更稳定 3. 更容易观测“为什么这次转发去了哪个后端、命中什么规则” B. 更强的安全能力(不仅是“允许/拒绝”) K8s 原生 NetworkPolicy 更多是 L3/L4(IP/端口)。Cilium 能做到更细: 1. 按 Pod 标签、命名空间、服务账户 做策略(身份感更强) 2. L7 策略(可选,通常依赖 Envoy): 3. 允许某些 HTTP Path / Method 4. gRPC 服务/方法级别控制 5. DNS 解析策略(允许访问哪些域名) C. 可观测性(排障神器) Cilium 自带/配套 Hubble(可选)可以做到: 1. 实时看流量(flow logs):谁访问了谁、是允许还是被拒绝、RTT、丢包 2. 快速定位:是 DNS 问题?策略拦了?还是 Service LB 选后端异常? D. 可选的高级能力(看你是否启用) 不同环境会选用其中一部分能力: 1. 透明加密(节点间/Pod 间加密) 2. BGP/路由通告(部分场景下替代或配合传统 LB) 3. Gateway API / Ingress(通过 cilium-envoy) 4. 多集群互联(ClusterMesh)三、cilium是怎么工作的(核心:eBPF 数据面)关键点:eBPF eBPF 是 Linux 内核机制,允许把程序挂到内核的网络钩子上(如 tc、XDP、cgroup),从而: 1. 在包进入/离开网卡、进入容器、进入 socket 前后做处理 2. 实现 NAT、负载均衡、策略过滤、可观测统计 3. 尽量减少 iptables 链式规则带来的复杂性 Cilium 常见组件(你 kubectl get pod -n kube-system 看到的那些) 1. cilium (DaemonSet):每个节点一个 agent,负责该节点上的转发/策略/eBPF 程序装载 2. cilium-operator (Deployment):做控制面工作(例如管理 IPAM、节点资源、状态同步等) 3. cilium-envoy (DaemonSet,可选):用于 L7 能力/Gateway/Ingress 等(不是所有场景都必须)四、IPAM 是什么IPAM = IP Address Management,就是“Pod 的 IP 从哪里来、怎么分配、怎么回收”。 Cilium 支持多种 IPAM 模式(不同环境选不同方式),常见两类理解: 1. kubernetes 模式:Pod IP 通常来自每个节点的 PodCIDR(例如你看到的 10.244.x.x) 2. cluster-pool / 等模式:由 Cilium 自己维护一个地址池分配(适合一些特定架构或需要 Cilium 管理地址的场景) 遇到的现象(Helm 改了 ipam.mode=kubernetes 但不重启不生效)很符合实际(后面案例): ConfigMap 改了 ≠ agent 自动 reload,Cilium agent 还是用旧配置跑着,所以要 rollout restart 让它重新读取配置并重新装载相关 datapath这两个模式本质上都在做一件事:给每个节点准备一段“Pod 子网(PodCIDR)”,然后由该节点上的 cilium-agent 在这段子网里给 Pod 分 IP。真正的核心区别只有一个: “每个节点的 PodCIDR 由谁来分配/作为事实来源(Source of Truth)? - cluster-pool / cluster-scope(默认):PodCIDR 由 Cilium Operator 分配,写到 v2.CiliumNode 里。 - kubernetes(Kubernetes Host Scope):PodCIDR 由 Kubernetes 分配,写到 v1.Node.spec.podCIDR(s) 里(依赖 kube-controller-manager 分配 Node CIDR)。cluster-pool / cluster-scope(Cilium 管 PodCIDR) 机制: - Cilium Operator 从你配置的 clusterPoolIPv4PodCIDRList 里切块,给每个节点分一个 PodCIDR,记录在 CiliumNode。 - 节点上的 cilium-agent 再从该 PodCIDR 里发放 Pod IP。 优点: - 不依赖 Kubernetes 给 Node 下发 PodCIDR:很多环境(尤其是你没法改 controller-manager 参数、或 K8s 不分配 PodCIDR 的场景)会更省事。 - 集群地址池扩容相对直观:池不够了可以往 clusterPoolIPv4PodCIDRList 追加新的 CIDR(注意是“追加”,不要改已有元素)。 - 支持 “集群多 CIDR”(多段池)——官方 IPAM 能力表里,cluster-scope 这一项是 缺点/坑点: - 和“标准 Kubernetes 语义”有点脱钩:因为 Node 的 spec.podCIDR 不是事实来源(可能为空或不一致),某些依赖 Node PodCIDR 的外部组件/脚本可能不适配(例如你自己写的自动化、某些网络周边控制器)。 - 默认池容易和节点网段冲突:文档明确提醒默认 10.0.0.0/8 如果跟节点网络重叠会直接炸(跨节点通信会被误判成 Pod 流量)。 - 控制面多了一个 CiliumNode(CRD)对象:排障时要懂它(但对运维来说也不算坏事)。ipam.mode=kubernetes(Kubernetes Host Scope,K8s 管 PodCIDR) 机制: - Cilium 从 Kubernetes Node 上读 spec.podCIDR(s),在该范围内分配 Pod IP。 - 文档强调:需要 kube-controller-manager 开启 --allocate-node-cidrs 才能给节点分 PodCIDR。 优点: - 最“原生 Kubernetes”:Node 的 spec.podCIDR 就是标准字段,很多周边组件、工具链、排障习惯都默认看它。 - 和集群初始化参数(如 kubeadm 的 --pod-network-cidr)天然一致:你想让 Pod 都落在 10.244.0.0/16 这种规划网段时更符合直觉。 - 配合云厂商/托管集群时,若平台本身就按 Node 分配 PodCIDR,这个模式更顺滑。 缺点: - 依赖 Kubernetes 能正确分配 Node PodCIDR:如果你的集群没开 allocate-node-cidrs、或托管环境不给 PodCIDR,这个模式会卡 Pod 分配/导致 Pod 起不来。 - “集群多 CIDR”不支持(能力表里 Kubernetes Host Scope 这项是 ❌)。 - 想扩容地址空间通常会牵涉更大范围的 K8s 网络规划调整(成本更高)。选哪个? 你能控制/确认 Kubernetes 会给 Node 分 PodCIDR(kubeadm 常见) → 优先选 ipam.mode=kubernetes:标准、兼容性好、排障直观。 你没法/不方便让 Kubernetes 分 PodCIDR,或希望 Cilium 自己掌控地址池(并可能需要多段 CIDR) → 选 cluster-pool/cluster-scope。Cilium 官方明确建议:不要在“存量集群”里随意切换 IPAM 模式,可能造成持续的网络中断风险;最安全是新集群按目标 IPAM 重装。你这次切换后通过重启恢复正常,说明你场景比较“干净”,但生产环境还是要非常谨慎。五、什么时候适合用 Cilium很适合这些场景: 1. 集群规模比较大、Service/Endpoint 多,追求性能和稳定性 2. 对 NetworkPolicy 有较强需求,想要更细粒度的安全控制 3. 经常排查网络问题,希望“看得见流量” 4. 想减少 kube-proxy/iptables 的复杂度 不一定要上满功能(比如 L7、Gateway、加密、BGP),很多团队只用它当高性能 CNI + NetworkPolicy + 可观测性,就已经很值了。六、ubuntu 22.04 部署Cilium前置条件(每个节点都要满足) Linux kernel ≥ 5.10(Ubuntu 22.04 默认一般是 5.15,通常没问题)。 uname -r6.1 方案 A:用 cilium-cli 快速安装(最省事)(我使用的是方案B)1) 安装 cilium-cli(在有 kubectl 的那台机器上) 按官方 quick install 文档的 Linux 安装方式: CILIUM_CLI_VERSION=$(curl -s https://raw.githubusercontent.com/cilium/cilium-cli/main/stable.txt) CLI_ARCH=amd64 if [ "$(uname -m)" = "aarch64" ]; then CLI_ARCH=arm64; fi curl -L --fail --remote-name-all \ https://github.com/cilium/cilium-cli/releases/download/${CILIUM_CLI_VERSION}/cilium-linux-${CLI_ARCH}.tar.gz{,.sha256sum} sha256sum --check cilium-linux-${CLI_ARCH}.tar.gz.sha256sum sudo tar xzvfC cilium-linux-${CLI_ARCH}.tar.gz /usr/local/bin rm cilium-linux-${CLI_ARCH}.tar.gz{,.sha256sum} 2) 安装 Cilium(作为 CNI) 官方示例(以文档当时的 stable 版本为例 1.18.5): cilium install --version 1.18.53) 验证 cilium status --wait cilium connectivity test6.2 方案 B:用 Helm 安装(方便走 GitOps/精细配置)官方 Helm 安装入口: 1) 添加 Helm 仓库并安装 helm repo add cilium https://helm.cilium.io/ helm repo update helm install cilium cilium/cilium --version 1.18.5 --namespace kube-system2) 验证 cilium status --wait cilium connectivity test # 安装前 root@k8s-master-01:~# ls -l /etc/cni/net.d/ total 8 -rw-r--r-- 1 root root 664 Dec 23 01:17 10-calico.conflist -rw------- 1 root root 2796 Dec 23 01:17 calico-kubeconfig # 安装后 会把calico重命名 默认使用的cilium root@k8s-master-02:~# ls -l /etc/cni/net.d/ total 12 -rw------- 1 root root 191 Dec 23 02:01 05-cilium.conflist -rw-r--r-- 1 root root 664 Dec 23 01:17 10-calico.conflist.cilium_bak -rw------- 1 root root 2796 Dec 23 01:17 calico-kubeconfig 6.3 此时集群有两个cni插件Calico 没删时,Cilium + Calico 会不会冲突? 默认会(除非你明确配置了 CNI chaining 让两者协同)。常见情况是: 1. 现有 Pod:基本还是走 Calico(它们创建时用的就是 Calico 的 CNI),短时间内通常还能通信。 2. 新建 Pod:如果 Cilium 已经把自己的 CNI 配置写进了 /etc/cni/net.d/,而且文件排序优先级比 Calico 高,那么新 Pod 可能会用 Cilium。这样集群就会出现“一部分 Pod 用 Calico,一部分用 Cilium”的混用状态——这时 Pod-Pod 通信非常容易出问题(跨节点路由/overlay/iptables/BPF 规则不一致)。 3. 另外,两套 agent 都在节点上跑,也可能同时改动路由、iptables、BPF 挂载/系统参数,带来不可预期的问题。 需要提前做好预案 删除calico的同时需要把所有的控制器资源如deploy 同时rollout restart 把cni切换成cilium否则就会出现上面说的情况6.4 升级切换# 这个看你需求上面有说 要说的一点是 改 ConfigMap 之后,Cilium agent / operator 通常需要重启才能读取新配置并重建 datapath。 root@k8s-master-01:~# helm upgrade cilium cilium/cilium \ -n kube-system \ --version 1.18.5 \ --reuse-values \ --set ipam.mode=kubernetes Release "cilium" has been upgraded. Happy Helming! NAME: cilium LAST DEPLOYED: Tue Dec 23 02:28:01 2025 NAMESPACE: kube-system STATUS: deployed REVISION: 2 TEST SUITE: None NOTES: You have successfully installed Cilium with Hubble. Your release version is 1.18.5. For any further help, visit https://docs.cilium.io/en/v1.18/gettinghelp kubectl -n kube-system rollout restart ds/cilium kubectl -n kube-system rollout restart ds/cilium-envoy kubectl -n kube-system rollout restart deploy/cilium-operator# 查看 给每个node节点分配的IP段 IPAM root@k8s-master-01:~# kubectl get node -o custom-columns=NAME:.metadata.name,PODCIDR:.spec.podCIDR,PODCIDRS:.spec.podCIDRs NAME PODCIDR PODCIDRS k8s-master-01 10.244.0.0/24 [10.244.0.0/24] k8s-master-02 10.244.1.0/24 [10.244.1.0/24] k8s-node-03 10.244.2.0/24 [10.244.2.0/24] k8s-node-04 10.244.3.0/24 [10.244.3.0/24] #为什么会有PODCIDRS和PODCIDR 这是因为k8s后面支持IPV4和IPV6 老的支持支单IP 新的支持数组 多IP配置root@k8s-master-01:~# kubectl get pod -n kube-system -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES cilium-envoy-655sx 1/1 Running 0 6h50m 192.168.30.160 k8s-master-01 <none> <none> cilium-envoy-6f6jv 1/1 Running 0 6h50m 192.168.30.163 k8s-node-04 <none> <none> cilium-envoy-7w54q 1/1 Running 0 6h50m 192.168.30.161 k8s-master-02 <none> <none> cilium-envoy-fg7q6 1/1 Running 0 6h50m 192.168.30.162 k8s-node-03 <none> <none> cilium-fsq6s 1/1 Running 0 6h50m 192.168.30.161 k8s-master-02 <none> <none> cilium-g4c79 1/1 Running 0 6h50m 192.168.30.162 k8s-node-03 <none> <none> cilium-jxmh5 1/1 Running 0 6h50m 192.168.30.160 k8s-master-01 <none> <none> cilium-operator-84cd4f9cb8-nqtlp 1/1 Running 0 6h50m 192.168.30.161 k8s-master-02 <none> <none> cilium-operator-84cd4f9cb8-vtphd 1/1 Running 0 6h50m 192.168.30.160 k8s-master-01 <none> <none> cilium-w4jqv 1/1 Running 0 6h50m 192.168.30.163 k8s-node-04 <none> <none> coredns-6d58d46f65-2sbtg 1/1 Running 0 6h50m 10.244.2.180 k8s-node-03 <none> <none> coredns-6d58d46f65-z4l4l 1/1 Running 0 6h50m 10.244.3.158 k8s-node-04 <none> <none> etcd-k8s-master-01 1/1 Running 5 (8h ago) 2d4h 192.168.30.160 k8s-master-01 <none> <none> etcd-k8s-master-02 1/1 Running 1 (8h ago) 2d3h 192.168.30.161 k8s-master-02 <none> <none> kube-apiserver-k8s-master-01 1/1 Running 2 (8h ago) 2d4h 192.168.30.160 k8s-master-01 <none> <none> kube-apiserver-k8s-master-02 1/1 Running 1 (8h ago) 2d3h 192.168.30.161 k8s-master-02 <none> <none> kube-controller-manager-k8s-master-01 1/1 Running 7 (8h ago) 2d4h 192.168.30.160 k8s-master-01 <none> <none> kube-controller-manager-k8s-master-02 1/1 Running 1 (8h ago) 2d3h 192.168.30.161 k8s-master-02 <none> <none> kube-proxy-44cbs 1/1 Running 1 (8h ago) 2d4h 192.168.30.160 k8s-master-01 <none> <none> kube-proxy-bjjb2 1/1 Running 1 (8h ago) 2d3h 192.168.30.163 k8s-node-04 <none> <none> kube-proxy-bvptw 1/1 Running 1 (8h ago) 2d3h 192.168.30.161 k8s-master-02 <none> <none> kube-proxy-m5dt2 1/1 Running 1 (8h ago) 2d3h 192.168.30.162 k8s-node-03 <none> <none> kube-scheduler-k8s-master-01 1/1 Running 6 (8h ago) 2d4h 192.168.30.160 k8s-master-01 <none> <none> kube-scheduler-k8s-master-02 1/1 Running 2 (8h ago) 2d3h 192.168.30.161 k8s-master-02 <none> <none> 只要你的业务是多副本/有滚动策略,通常只是“抖一下”,不会全断;单副本服务会有短暂不可用,这是任何 CNI 迁移都绕不开的。 #部署前 root@k8s-master-01:~# ls -l /etc/cni/net.d/ total 8 -rw-r--r-- 1 root root 664 Dec 23 01:17 10-calico.conflist -rw------- 1 root root 2796 Dec 23 01:17 calico-kubeconfig #部署后 会把calico重命名 后续pod的创建会默认走cilium 所以cilium启动好后 需要把所有业务pod 都重启一遍 root@k8s-master-01:~# ls -l /etc/cni/net.d/ total 12 -rw------- 1 root root 191 Dec 23 02:03 05-cilium.conflist -rw-r--r-- 1 root root 664 Dec 23 01:17 10-calico.conflist.cilium_bak -rw------- 1 root root 2796 Dec 23 01:17 calico-kubeconfig七、Cilium组件 7.1 Cilium Agent(DaemonSet,每节点 1 个)这是 Cilium 的核心,每个节点都必须有。 主要功能: eBPF 数据面加载与维护 - 在节点内核里加载 eBPF 程序(TC/XDP、cgroup hooks 等),实现 Pod 之间转发、Service 负载均衡、网络策略等。 - 维护 Cilium 的 BPF maps(相当于内核里的高性能“路由/连接/策略表”)。 管理 Pod/Endpoint 生命周期 - 监听 K8s(Pod/Service/EndpointSlice/Node 等)变化,创建/更新 CiliumEndpoint 等资源。 - 负责把“这个 Pod 的 IP/身份/策略”下发到本节点的数据面。 Kubernetes Service 转发(L4) - 用 eBPF 做 Service 的四层负载均衡、DNAT/SNAT、session affinity 等(即使你没开 kube-proxy replacement,也会参与很多转发能力)。 NetworkPolicy 落地 - 处理 K8s NetworkPolicy / CiliumNetworkPolicy / CiliumClusterwideNetworkPolicy,转换成 eBPF 可执行的规则。 可选能力 - Hubble(可观测)、加密(WireGuard/IPsec)、eBPF HostRouting、Egress Gateway、带宽管理等(取决于你装的时候开没开)。 一句话:cilium Pod 就是每个节点的“网络内核驱动 + 控制代理”。7.2 Envoy 代理(DaemonSet,每节点 1 个)这是 L7/Ingress/Gateway API 等功能的“七层代理执行器”。 Cilium 本身用 eBPF 擅长 L3/L4(IP/端口/连接层面的东西),但如果你要做这些就需要 Envoy: - L7 网络策略(HTTP/gRPC/Kafka 等按域名、路径、方法、Header 的策略) - Ingress / Gateway API(很多场景由 Envoy 承担实际转发) - TLS 终止/重加密、L7 可观测(看你启用的功能) 工作方式通常是: - cilium agent 用 eBPF 把某些流量“重定向”给本机的 cilium-envoy - Envoy 做完七层处理后再把流量送回去继续转发 一句话:cilium-envoy 是 Cilium 的 L7 扩展引擎。7.3 Cilium Operator(Deployment,集群级 1~2 个)这是 集群级控制面组件,不需要每节点一个。 它主要负责“跨节点/全局”的事情,比如: 1.IPAM/地址相关的集群级管理 - 你现在 ipam: kubernetes:PodCIDR 是 Kubernetes 控制器分给 Node 的,agent 按 Node 的 PodCIDR 分配 Pod IP。 - 即便如此,operator 仍会参与一些 Node/CRD 的维护工作(不同版本细节略有差异)。 2.LB-IPAM(你已经开启) - 你 config 里 enable-lb-ipam: "true"、default-lb-service-ipam: lbipam - 这意味着:当你创建 type: LoadBalancer 的 Service 时,Cilium 可以用 LB-IPAM 给它分配外部 IP(来自你配置的地址池/策略)。 - 这类“全局分配/回收”的事通常由 operator 负责协调,agent 负责在节点上落实转发。 3.管理/清理一些全局资源 - 例如身份(identity)相关、旧对象回收、状态一致性维护等(具体看你启用的功能和版本)。 一句话:cilium-operator 是 Cilium 的“集群级大管家”,负责全局资源协调。八、开启UI#最简单一把梭 helm upgrade cilium cilium/cilium -n kube-system --version 1.18.5 --reuse-values \ --set hubble.relay.enabled=true \ --set hubble.ui.enabled=true \ --set hubble.ui.service.type=NodePort 九、开启kube-proxy-free 代替集群原来的 kube-proxy用 kubeconfig 里的 server 作为 k8sServiceHost 在 master 上执行,看看你的 kubeconfig 当前指向哪个 apiserver(通常是 VIP/LB,强烈建议用 VIP/LB,不要写死单个 master IP): root@k8s-master-01:~# kubectl config view --minify -o jsonpath='{.clusters[0].cluster.server}'; echo https://192.168.30.58:16443 helm upgrade cilium cilium/cilium -n kube-system --version 1.18.5 --reuse-values \ --set kubeProxyReplacement=true \ --set k8sServiceHost=192.168.30.58 \ --set k8sServicePort=6443 kubectl -n kube-system rollout restart ds/cilium kubectl -n kube-system rollout restart deploy/cilium-operator 验证是否开启 root@k8s-master-01:~# kubectl -n kube-system exec ds/cilium -- cilium-dbg status | grep KubeProxyReplacement KubeProxyReplacement: True [ens33 192.168.30.160 192.168.30.58 fe80::20c:29ff:fef6:2d (Direct Routing)]#备份 kubectl -n kube-system get ds kube-proxy -o yaml > kube-proxy.ds.yaml kubectl -n kube-system get cm kube-proxy -o yaml > kube-proxy.cm.yaml #删除 kube-proxy DaemonSet + ConfigMap(官方推荐连 CM 也删,避免 kubeadm 升级时装回来 kubectl -n kube-system delete ds kube-proxy kubectl -n kube-system delete cm kube-proxy #每个节点清理遗留 KUBE* iptables 规则(官方给的命令) 不能随便执行 如果你节点上面有特定的规则 还有就是执行后 ssh会连接不上 实在要执行先执行前面这两条 保证ssh和已建立连接永久放行 iptables -I INPUT 1 -m conntrack --ctstate ESTABLISHED,RELATED -j ACCEPT iptables -I INPUT 2 -p tcp --dport 22 -j ACCEPT iptables-save | grep -v KUBE | iptables-restore十、开启Gateway api#安装 Gateway API 的 standard CRDs(否则 apiserver 里没有 Gateway/GatewayClass/HTTPRoute 这些资源) kubectl apply --server-side=true -f \ https://github.com/kubernetes-sigs/gateway-api/releases/download/v1.2.0/standard-install.yaml #在 Cilium 里开启 Gateway API Controller helm upgrade cilium cilium/cilium -n kube-system --version 1.18.5 --reuse-values \ --set gatewayAPI.enabled=true#选择暴露方式(二选一) 有 LoadBalancer 能力(云 LB / MetalLB):不用 hostNetwork(默认走 LB Service) 没有 LoadBalancer 能力(你这种裸金属常见):开启 hostNetwork helm upgrade cilium cilium/cilium -n kube-system --version 1.18.5 --reuse-values \ --set gatewayAPI.enabled=true \ --set gatewayAPI.hostNetwork.enabled=true#案例 root@k8s-master-01:~# cat nginx.yaml apiVersion: v1 kind: Namespace metadata: name: webs --- apiVersion: apps/v1 kind: Deployment metadata: name: nginx namespace: webs spec: replicas: 1 selector: matchLabels: app: nginx template: metadata: labels: app: nginx spec: containers: - name: nginx image: registry.cn-guangzhou.aliyuncs.com/xingcangku/nginx:1.18 ports: - containerPort: 80 --- apiVersion: v1 kind: Service metadata: name: nginx-svc namespace: webs spec: selector: app: nginx ports: - name: http port: 80 targetPort: 80 --- apiVersion: gateway.networking.k8s.io/v1 kind: Gateway metadata: name: nginx-gw namespace: webs spec: gatewayClassName: cilium listeners: - name: http protocol: HTTP port: 8080 hostname: nginx.axzys.cn allowedRoutes: namespaces: from: Same --- apiVersion: gateway.networking.k8s.io/v1 kind: HTTPRoute metadata: name: nginx-route namespace: webs spec: parentRefs: - name: nginx-gw sectionName: http hostnames: - nginx.axzys.cn rules: - matches: - path: type: PathPrefix value: / backendRefs: - name: nginx-svc port: 80 root@k8s-node-04:~# curl -H 'Host: nginx.axzys.cn' http://192.168.30.160:8080/ no healthy upstreamroot@k8s-node-04:~# curl -H 'Host: nginx.axzys.cn' http://192.168.30.160:8080/ no healthy upstreamrcurl -H 'Host: nginx.axzys.cn' http://192.168.30.160:8080/ | head30.160:8080/ | head % Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 100 612 100 612 0 0 21315 0 --:--:-- --:--:-- --:--:-- 21857 <!DOCTYPE html> <html> <head> <title>Welcome to nginx!</title> <style> body { width: 35em; margin: 0 auto; font-family: Tahoma, Verdana, Arial, sans-serif; } 在浏览器中显示需要hosts文件中添加上
-
Ansible ubuntu 22.04 双主 这个文件一共 两个 play: Play 1(localhost):只在控制机(你现在跑 ansible 的那台)做准备工作:生成/读取 SSH 公钥、写 ssh config、准备离线目录、尝试下载 k8s apt keyring(可选、失败不报错)。 Play 2(k8s_cluster):对所有 k8s 节点做“真正的装机 + Kubernetes 初始化/加入”流程:系统基础配置、离线 apt repo 挂载、安装 containerd/k8s 组件、VIP 负载均衡(haproxy+keepalived,仅 master)、kubeadm init(首个 master)、其余 master join、worker join。Play 1:Prepare controller SSH key (localhost) 目标:让控制机具备 SSH key,并把公钥内容作为 fact 传给后续 play 使用。 关键点: 1.确保 ~/.ssh 存在 file 创建目录、权限 0700。 2.若缺失则生成 SSH key ssh-keygen -t rsa -b 4096 -N "" -f "{{ controller_ssh_key }}" creates: 保证幂等:文件存在则不再执行。 3.读取控制机公钥并 set_fact slurp 会把文件内容 base64 读回来;再 b64decode 变成文本。 存到 controller_pubkey,供后续节点写入 authorized_keys。 4.可选:写入控制机的 ~/.ssh/config 对 192.168.30.* 统一指定: 用户 root IdentityFile 使用 controller 生成的 key StrictHostKeyChecking no / UserKnownHostsFile /dev/null(方便自动化,但安全性降低) 这一步不影响节点配置,只是让你控制机 ssh 更省事。 5.确保 files/offline 目录存在 后续用到离线包、keyring 都放在 files/offline。 6.尝试下载 kubernetes apt keyring(最佳努力,不失败) failed_when: false + changed_when: false 有网就生成 kubernetes-apt-keyring.gpg,没网也继续往下跑。 随后 stat 检测是否存在,并设置 controller_has_k8s_keyring。 注意:你这里的离线 repo list 使用了 trusted=yes,所以 即使没有 keyring 也能装。但保留 keyring 逻辑可以让你以后切回在线源/或者取消 trusted=yes 更安全。Play 2:Bootstrap all k8s nodes(核心) 2.1 vars:整套集群“参数中心” ssh_user / ssh_user_home:依据 ansible_user 判断是 /root 还是 /home/<user>,用来给该用户写 authorized_keys。 VIP / keepalived / haproxy: apiserver_vip=192.168.30.58 apiserver_vip_port=16443(VIP 对外暴露端口) apiserver_bind_port=6443(kube-apiserver 实际监听端口) apiserver_vip_iface:用默认网卡名(拿 facts) keepalived_virtual_router_id/auth_pass:VRRP 参数 离线 repo: offline_tools_repo_tar、offline_containerd_repo_tar、offline_k8s_repo_tar、offline_lb_repo_tar 以及对应解压目录、apt list 文件路径 k8s 版本: k8s_pkg_version: 1.30.14-1.1 kubeadm_kubernetes_version: v1.30.14 kubeadm_image_repository:你用阿里镜像仓库,适合国内/离线镜像同步场景 containerd: containerd_sandbox_image 指定 pause 镜像 SystemdCgroup=true 内核模块:overlay、br_netfilter、ipvs 一套 + nf_conntrack 集群网络:pod/service 子网、domain、cri socket LB 节点选择逻辑(很关键): lb_masters: "{{ (groups['k8s_cluster'] | select('search','master') | list | sort)[:2] }}" 从 inventory 里挑主机名含 master 的,排序后取前两个作为“做 VIP LB 的两台 master” init_master: "{{ lb_masters[0] }}":第一台 master 作为 kubeadm init 节点 is_lb_master/is_init_master:根据当前 host 判断分支执行 注意:这个选择逻辑 强依赖你的 inventory 主机名里包含 master,且至少有 2 台;否则 haproxy 配置那里引用 lb_masters[1] 会出问题。 2.2 apt 源清理:避免离线环境 apt 卡死 注释 /etc/apt/sources.list 和 /etc/apt/sources.list.d/*.list 里 deb cdrom: 行 离线环境最常见问题就是 apt update 时尝试访问 cdrom 或不可达源导致报错/卡住,这里算是“保险丝”。 2.3 主机基础:hostname、/etc/hosts、SSH 信任 hostname 设置为 inventory_hostname 生成 k8s_hosts_block:把所有节点 IP + 主机名写进 blockinfile 写入 /etc/hosts(保证节点互相能用主机名解析) 写 authorized_keys: 给 ansible_user 和 root 都写入控制机公钥(让控制机免密登录节点) 给 root 再写入“所有节点之间互信”的 key(node<->node) 配 sshd drop-in: PermitRootLogin prohibit-password(允许 root 使用公钥登录) PasswordAuthentication no(禁用密码登录) 并触发 handler restart ssh 风险提示:如果你原本靠密码/其他方式登录,禁用密码可能把你锁在门外。好在你的流程先把公钥塞进去再禁用密码,逻辑上是对的,但仍建议谨慎在生产环境使用。 2.4 swap & 内核参数:Kubernetes 前置条件 swapoff -a + 注释 /etc/fstab 里 swap 行(避免重启恢复) 写 /etc/modules-load.d/k8s.conf 并 modprobe 写 /etc/sysctl.d/99-kubernetes-cri.conf 并 sysctl --system 包括桥接流量、ip_forward、nonlocal_bind(VIP 常用) 2.5 离线 apt repo:解压、自动定位 Packages.gz、写 file: 源 流程对每个 repo 都类似: 确保 /opt/offline-repos 存在 解压 tar.gz 到对应目录 find Packages.gz,取其所在目录当“repo root” 写 deb [trusted=yes] file:<repo_root> ./ apt update 刷缓存 安装 packages trusted=yes 让 apt 不校验签名,离线很好用,但安全性降低;如果你已经有 keyring/签名,也可以改为不 trusted 并正确配 key。 2.6 containerd:配置 CRI、启动服务 安装 containerd/runc(来自离线 repo) 写 /etc/containerd/config.toml sandbox_image 指定 pause snapshotter=overlayfs SystemdCgroup=true registry mirrors 里 docker.io 指向 registry-1(若离线环境不出网,拉 docker.io 仍会失败——通常你会提前把镜像导入,或搭私有 registry) systemd 启动并 enable 写 /etc/crictl.yaml 让 crictl 默认连 containerd 2.7 kubeadm/kubelet/kubectl:离线安装 + hold 可选复制 kubernetes apt keyring 到节点 /etc/apt/keyrings 安装固定版本 kubeadm/kubelet/kubectl + 依赖(kubernetes-cni、cri-tools…) apt-mark hold 锁版本 启动 kubelet(此时可能还会报错是正常的,直到 kubeadm init/join 完成) 2.8 VIP LB(仅两台 master):haproxy + keepalived 两台 master 安装 haproxy、keepalived haproxy: 监听 *:16443 后端转发到两台 master 的 :6443 keepalived: check_haproxy.sh:只检查 haproxy 进程是否存在 两台都用 state BACKUP,用优先级决定谁抢到 VIP virtual_ipaddress 配 VIP/24 track_script 绑定健康检查 启动并 enable;等待本地 16443 端口起来 这套结构就是:VIP(16443) -> haproxy -> master(6443) kubeadm 的 controlPlaneEndpoint 指向 VIP:16443,所以集群内外都走 VIP。 2.9 kubeadm init(仅 init master) 先检查 /etc/kubernetes/admin.conf 是否存在,存在说明已经初始化过,避免重复 init 写 /root/kubeadm.yaml apiVersion: kubeadm.k8s.io/v1beta3(你已经标注了“修复2:v1beta4 -> v1beta3”) controlPlaneEndpoint: VIP:16443 imageRepository 指向阿里 apiServer.certSANs 包含 VIP、两台 master IP/hostname、localhost InitConfiguration 里: advertiseAddress 用本机 IP bindPort 用 6443 nodeRegistration 设置 cri socket 和 node-ip 执行 kubeadm init(带 --upload-certs,并忽略 SystemVerification、Swap) 把 admin.conf 拷贝到 /root/.kube/config 方便 kubectl 生成 join 命令: worker join command:kubeadm token create --print-join-command 控制面 join 需要 --control-plane --certificate-key <key> kubeadm init phase upload-certs --upload-certs 输出里抓 64 位 hex key 把 join 命令写成脚本 /root/join-worker.sh、/root/join-controlplane.sh 最关键的一步:把 join 命令通过 delegate_to: localhost + delegate_facts: true 变成“全局事实”,让后续其他节点能引用: hostvars['localhost'].global_join_worker hostvars['localhost'].global_join_cp 2.10 其余节点 join 先看 /etc/kubernetes/kubelet.conf 是否存在(存在说明已 join) 第二台 master(is_lb_master 且 not is_init_master): 运行 global_join_cp 加入控制面 worker: 运行 global_join_worker handlers:服务重启 containerd、haproxy、keepalived、ssh 的 restart 都集中在 handlers 由上面 tasks 的 notify 触发,符合 ansible 最佳实践--- ############################################################################### # Play 1: 仅在控制机(localhost)执行 # 目的: # 1) 生成/准备控制机 SSH key(用于免密登录所有节点) # 2) 读取控制机公钥,保存为 fact,供后续 play 写入各节点 authorized_keys # 3) 准备离线目录与(可选)kubernetes apt keyring 文件 ############################################################################### - name: Prepare controller SSH key (localhost) hosts: localhost gather_facts: false tasks: # 确保控制机 ~/.ssh 目录存在 - name: Ensure ~/.ssh exists on controller ansible.builtin.file: path: "{{ lookup('env','HOME') + '/.ssh' }}" state: directory mode: "0700" # 若 controller_ssh_key 不存在则生成(幂等:creates 控制) - name: Generate SSH key on controller if missing ansible.builtin.command: > ssh-keygen -t rsa -b 4096 -N "" -f "{{ controller_ssh_key }}" args: creates: "{{ controller_ssh_key }}" # 读取控制机公钥(slurp 返回 base64) - name: Read controller public key ansible.builtin.slurp: src: "{{ controller_ssh_pub }}" register: controller_pubkey_raw # 将 base64 解码成文本形式的公钥,保存为 controller_pubkey(供后续 hostvars['localhost'] 引用) - name: Set controller_pubkey fact ansible.builtin.set_fact: controller_pubkey: "{{ controller_pubkey_raw.content | b64decode }}" # 可选:写入控制机 ~/.ssh/config,方便你从控制机 ssh 到 192.168.30.* 网段 # 注意:StrictHostKeyChecking no 会降低安全性,但便于自动化环境 - name: Ensure controller ssh config includes cluster rule (optional but recommended) ansible.builtin.blockinfile: path: "{{ lookup('env','HOME') + '/.ssh/config' }}" create: true mode: "0600" marker: "# {mark} ANSIBLE K8S CLUSTER SSH" block: | Host 192.168.30.* User root IdentityFile {{ controller_ssh_key }} IdentitiesOnly yes StrictHostKeyChecking no UserKnownHostsFile /dev/null # 确保项目的离线文件目录存在(tar.gz、keyring 等都在这里) - name: Ensure files/offline exists on controller ansible.builtin.file: path: "{{ playbook_dir }}/../files/offline" state: directory mode: "0755" # 尝试在线下载 kubernetes apt keyring(最佳努力:失败不报错) # 离线环境没网也没关系,你目录里已有 kubernetes-apt-keyring.gpg 的话同样可用 - name: Try to generate kubernetes apt keyring on controller if missing (best effort, no-fail) ansible.builtin.shell: | set -e curl -fsSL --connect-timeout 5 --max-time 20 https://pkgs.k8s.io/core:/stable:/v1.30/deb/Release.key \ | gpg --dearmor -o "{{ playbook_dir }}/../files/offline/kubernetes-apt-keyring.gpg" args: creates: "{{ playbook_dir }}/../files/offline/kubernetes-apt-keyring.gpg" changed_when: false failed_when: false # 检测 keyring 是否存在 - name: Check kubernetes apt keyring exists on controller ansible.builtin.stat: path: "{{ playbook_dir }}/../files/offline/kubernetes-apt-keyring.gpg" register: controller_k8s_keyring_stat # 设置一个布尔 fact,供后续 play 决定要不要复制 keyring 到节点 - name: Set controller_has_k8s_keyring fact ansible.builtin.set_fact: controller_has_k8s_keyring: "{{ controller_k8s_keyring_stat.stat.exists | default(false) }}" ############################################################################### # Play 2: 对所有 k8s 节点执行(hosts: k8s_cluster) # 目的(大而全): # - 系统基础:hostname、/etc/hosts、关闭 swap、内核模块与 sysctl # - SSH:控制机 -> 节点免密;节点之间 root 互信(node<->node) # - 离线安装:解压离线 repo,写 file: apt 源,apt 安装工具/容器运行时/k8s 组件 # - master VIP:haproxy + keepalived 提供 apiserver VIP 入口 # - kubeadm:init 首个 master;其余 master/worker join ############################################################################### - name: Bootstrap all k8s nodes (hostname, /etc/hosts, SSH trust, offline tools, kernel modules, containerd, k8s pkgs, swapoff, apiserver VIP LB, kubeadm init/join) hosts: k8s_cluster become: true gather_facts: true vars: # 当前 ansible 连接用户及其 home(用于写 authorized_keys) ssh_user: "{{ ansible_user }}" ssh_user_home: "{{ '/root' if ssh_user == 'root' else '/home/' ~ ssh_user }}" # apiserver VIP(对外入口),以及 VIP 对外端口与 apiserver 实际 bind 端口 apiserver_vip: "192.168.30.58" apiserver_vip_port: 16443 apiserver_bind_port: 6443 # keepalived 使用的网卡(默认取 facts 的默认网卡,否则 ens33) apiserver_vip_iface: "{{ ansible_default_ipv4.interface | default('ens33') }}" keepalived_virtual_router_id: 51 keepalived_auth_pass: "k8sVIP@2025" # ------------------------- # 离线 repo:系统工具 # ------------------------- offline_tools_repo_tar: "{{ playbook_dir }}/../files/offline/os-tools-repo-ipvs.tar.gz" offline_tools_repo_dir: "/opt/offline-repos/os-tools-ipvs" offline_tools_repo_list: "/etc/apt/sources.list.d/offline-os-tools-ipvs.list" offline_tools_packages: - expect - wget - jq - psmisc - vim - net-tools - telnet - lvm2 - git - ntpdate - chrony - bind9-utils - rsync - unzip - ipvsadm - ipset - sysstat - conntrack # ------------------------- # 离线 repo:containerd # ------------------------- offline_containerd_repo_tar: "{{ playbook_dir }}/../files/offline/containerd-repo.tar.gz" offline_containerd_repo_dir: "/opt/offline-repos/containerd" offline_containerd_repo_list: "/etc/apt/sources.list.d/offline-containerd.list" offline_containerd_packages: - containerd - runc # ------------------------- # 离线 repo:haproxy/keepalived(仅 master 用) # ------------------------- offline_lb_repo_tar: "{{ playbook_dir }}/../files/offline/nginx-keepalived-repo.tar.gz" offline_lb_repo_dir: "/opt/offline-repos/nginx-keepalived" offline_lb_repo_list: "/etc/apt/sources.list.d/offline-nginx-keepalived.list" # ------------------------- # Kubernetes 版本与镜像仓库 # ------------------------- k8s_pkg_version: "1.30.14-1.1" kubeadm_kubernetes_version: "v1.30.14" kubeadm_image_repository: "registry.cn-hangzhou.aliyuncs.com/google_containers" # containerd pause 镜像(pod sandbox) containerd_sandbox_image: "registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.9" containerd_config: "/etc/containerd/config.toml" # ------------------------- # 离线 repo:Kubernetes apt 仓库 # ------------------------- offline_k8s_repo_tar: "{{ playbook_dir }}/../files/offline/k8s-repo-v1.30.14-1.1.tar.gz" offline_k8s_repo_dir: "/opt/offline-repos/k8s-v1.30.14-1.1" offline_k8s_repo_list: "/etc/apt/sources.list.d/offline-k8s-v1.30.14-1.1.list" # Kubernetes keyring(如果控制机存在,就复制到节点) offline_k8s_keyring_src: "{{ playbook_dir }}/../files/offline/kubernetes-apt-keyring.gpg" offline_k8s_keyring_dest: "/etc/apt/keyrings/kubernetes-apt-keyring.gpg" # k8s 组件及依赖(kubeadm/kubelet/kubectl 固定版本安装) offline_k8s_packages: - "kubeadm={{ k8s_pkg_version }}" - "kubelet={{ k8s_pkg_version }}" - "kubectl={{ k8s_pkg_version }}" - kubernetes-cni - cri-tools - socat - ebtables - ethtool - apt-transport-https # ipvs 与 k8s 常用模块 ipvs_modules: - ip_vs - ip_vs_rr - ip_vs_wrr - ip_vs_sh - nf_conntrack k8s_modules: - overlay - br_netfilter # 集群网络参数 pod_subnet: "10.244.0.0/16" service_subnet: "10.96.0.0/12" cluster_domain: "cluster.local" cri_socket: "unix:///run/containerd/containerd.sock" # 从 inventory 中挑选主机名包含 master 的节点,排序取前两台作为 LB master # 第 1 台同时作为 kubeadm init 节点 lb_masters: "{{ (groups['k8s_cluster'] | select('search','master') | list | sort)[:2] }}" is_lb_master: "{{ inventory_hostname in lb_masters }}" init_master: "{{ lb_masters[0] }}" is_init_master: "{{ inventory_hostname == init_master }}" tasks: # ------------------------- # apt 源清理:禁用 cdrom 源(离线环境常见坑) # ------------------------- - name: Disable CDROM apt source in /etc/apt/sources.list (comment deb cdrom:) ansible.builtin.replace: path: /etc/apt/sources.list regexp: '^deb\s+cdrom:' replace: '# deb cdrom:' failed_when: false - name: Find .list files under /etc/apt/sources.list.d ansible.builtin.find: paths: /etc/apt/sources.list.d patterns: "*.list" file_type: file register: apt_list_files failed_when: false - name: Disable CDROM apt source in sources.list.d files (comment deb cdrom:) ansible.builtin.replace: path: "{{ item.path }}" regexp: '^deb\s+cdrom:' replace: '# deb cdrom:' loop: "{{ apt_list_files.files | default([]) }}" failed_when: false # ------------------------- # 主机名与 hosts 解析:确保节点互相能解析主机名 # ------------------------- - name: Set hostname ansible.builtin.hostname: name: "{{ inventory_hostname }}" - name: Build hosts block for all cluster nodes ansible.builtin.set_fact: k8s_hosts_block: | {% for h in groups['k8s_cluster'] | sort %} {{ hostvars[h].ansible_default_ipv4.address }} {{ h }} {% endfor %} - name: Ensure /etc/hosts contains cluster nodes mapping ansible.builtin.blockinfile: path: /etc/hosts marker: "# {mark} ANSIBLE K8S CLUSTER HOSTS" block: "{{ k8s_hosts_block }}" # ------------------------- # SSH 免密:控制机 -> 节点(ansible_user 与 root) # ------------------------- - name: Ensure ansible user .ssh dir exists ansible.builtin.file: path: "{{ ssh_user_home }}/.ssh" state: directory mode: "0700" owner: "{{ ssh_user }}" group: "{{ ssh_user }}" - name: Add controller pubkey to ansible user authorized_keys ansible.builtin.lineinfile: path: "{{ ssh_user_home }}/.ssh/authorized_keys" create: true mode: "0600" owner: "{{ ssh_user }}" group: "{{ ssh_user }}" line: "{{ hostvars['localhost'].controller_pubkey | default('') }}" when: (hostvars['localhost'].controller_pubkey | default('')) | length > 0 - name: Ensure root .ssh dir exists ansible.builtin.file: path: /root/.ssh state: directory mode: "0700" - name: Add controller pubkey to root authorized_keys ansible.builtin.lineinfile: path: /root/.ssh/authorized_keys create: true mode: "0600" line: "{{ hostvars['localhost'].controller_pubkey | default('') }}" when: (hostvars['localhost'].controller_pubkey | default('')) | length > 0 # ------------------------- # SSHD 策略:允许 root 公钥登录,但不禁用密码登录 # ------------------------- - name: Ensure sshd drop-in dir exists ansible.builtin.file: path: /etc/ssh/sshd_config.d state: directory mode: "0755" - name: Allow root login with publickey (drop-in) and keep password login enabled ansible.builtin.copy: dest: /etc/ssh/sshd_config.d/99-ansible-rootlogin.conf mode: "0644" content: | PermitRootLogin prohibit-password PubkeyAuthentication yes PasswordAuthentication yes notify: Restart ssh # ------------------------- # 节点之间 root 互信:node <-> node # 思路:每个节点生成自己的 /root/.ssh/id_rsa,然后把所有节点的公钥汇总写到每台的 authorized_keys # ------------------------- - name: Generate node SSH key if missing ansible.builtin.command: ssh-keygen -t rsa -b 4096 -N "" -f /root/.ssh/id_rsa args: creates: /root/.ssh/id_rsa - name: Read node public key ansible.builtin.slurp: src: /root/.ssh/id_rsa.pub register: node_pubkey_raw - name: Set node_pubkey_text fact ansible.builtin.set_fact: node_pubkey_text: "{{ node_pubkey_raw.content | b64decode | trim }}" - name: Add all nodes keys to every node authorized_keys (node <-> node) ansible.builtin.lineinfile: path: /root/.ssh/authorized_keys create: true mode: "0600" line: "{{ hostvars[item].node_pubkey_text }}" loop: "{{ groups['k8s_cluster'] | sort }}" when: hostvars[item].node_pubkey_text is defined # ------------------------- # swap:k8s 要求关闭 swap # ------------------------- - name: Disable swap immediately ansible.builtin.command: swapoff -a changed_when: false failed_when: false - name: Comment swap in /etc/fstab ansible.builtin.replace: path: /etc/fstab regexp: '^(\s*[^#\n]+\s+[^ \n]+\s+swap\s+[^ \n]+.*)$' replace: '# \1' failed_when: false # ------------------------- # 内核模块与 sysctl:k8s + ipvs 常规前置 # ------------------------- - name: Ensure k8s modules-load file ansible.builtin.copy: dest: /etc/modules-load.d/k8s.conf mode: "0644" content: | overlay br_netfilter ip_vs ip_vs_rr ip_vs_wrr ip_vs_sh nf_conntrack - name: Modprobe required modules ansible.builtin.command: "modprobe {{ item }}" loop: "{{ k8s_modules + ipvs_modules }}" changed_when: false failed_when: false - name: Ensure sysctl for Kubernetes ansible.builtin.copy: dest: /etc/sysctl.d/99-kubernetes-cri.conf mode: "0644" content: | net.bridge.bridge-nf-call-iptables = 1 net.bridge.bridge-nf-call-ip6tables = 1 net.ipv4.ip_forward = 1 net.ipv4.ip_nonlocal_bind = 1 - name: Apply sysctl ansible.builtin.command: sysctl --system changed_when: false # ------------------------- # 离线 repo:目录准备 # ------------------------- - name: Ensure offline repos base dir exists ansible.builtin.file: path: /opt/offline-repos state: directory mode: "0755" - name: Ensure offline repo dirs exist ansible.builtin.file: path: "{{ item }}" state: directory mode: "0755" loop: - "{{ offline_tools_repo_dir }}" - "{{ offline_containerd_repo_dir }}" - "{{ offline_k8s_repo_dir }}" - "{{ offline_lb_repo_dir }}" # ------------------------- # 离线 repo:系统工具 repo(解压 -> 自动定位 Packages.gz -> 写 file: 源) # ------------------------- - name: Unpack offline tools repo ansible.builtin.unarchive: src: "{{ offline_tools_repo_tar }}" dest: "{{ offline_tools_repo_dir }}" - name: Find Packages.gz for offline tools repo (auto-detect repo root) ansible.builtin.find: paths: "{{ offline_tools_repo_dir }}" patterns: "Packages.gz" recurse: true register: tools_pkg_index - name: Set offline tools repo root ansible.builtin.set_fact: offline_tools_repo_root: "{{ (tools_pkg_index.files | first).path | dirname }}" when: (tools_pkg_index.matched | int) > 0 - name: Write offline tools apt source list ansible.builtin.copy: dest: "{{ offline_tools_repo_list }}" mode: "0644" content: | deb [trusted=yes] file:{{ offline_tools_repo_root | default(offline_tools_repo_dir) }} ./ # ------------------------- # 离线 repo:containerd repo(解压 -> 自动定位 Packages.gz -> 写 file: 源) # ------------------------- - name: Unpack offline containerd repo ansible.builtin.unarchive: src: "{{ offline_containerd_repo_tar }}" dest: "{{ offline_containerd_repo_dir }}" - name: Find Packages.gz for offline containerd repo (auto-detect repo root) ansible.builtin.find: paths: "{{ offline_containerd_repo_dir }}" patterns: "Packages.gz" recurse: true register: containerd_pkg_index - name: Set offline containerd repo root ansible.builtin.set_fact: offline_containerd_repo_root: "{{ (containerd_pkg_index.files | first).path | dirname }}" when: (containerd_pkg_index.matched | int) > 0 - name: Write offline containerd apt source list ansible.builtin.copy: dest: "{{ offline_containerd_repo_list }}" mode: "0644" content: | deb [trusted=yes] file:{{ offline_containerd_repo_root | default(offline_containerd_repo_dir) }} ./ # ------------------------- # 离线 repo:k8s repo(解压 -> 自动定位 Packages.gz -> 写 file: 源) # ------------------------- - name: Unpack offline kubernetes repo ansible.builtin.unarchive: src: "{{ offline_k8s_repo_tar }}" dest: "{{ offline_k8s_repo_dir }}" - name: Find Packages.gz for offline kubernetes repo (auto-detect repo root) ansible.builtin.find: paths: "{{ offline_k8s_repo_dir }}" patterns: "Packages.gz" recurse: true register: k8s_pkg_index - name: Set offline kubernetes repo root ansible.builtin.set_fact: offline_k8s_repo_root: "{{ (k8s_pkg_index.files | first).path | dirname }}" when: (k8s_pkg_index.matched | int) > 0 - name: Write offline kubernetes apt source list ansible.builtin.copy: dest: "{{ offline_k8s_repo_list }}" mode: "0644" content: | deb [trusted=yes] file:{{ offline_k8s_repo_root | default(offline_k8s_repo_dir) }} ./ # ------------------------- # 离线 repo:LB repo(仅 master,且 best effort) # ------------------------- - name: Unpack offline LB repo (masters only, best effort) ansible.builtin.unarchive: src: "{{ offline_lb_repo_tar }}" dest: "{{ offline_lb_repo_dir }}" when: is_lb_master failed_when: false - name: Find Packages.gz for offline LB repo (auto-detect repo root) ansible.builtin.find: paths: "{{ offline_lb_repo_dir }}" patterns: "Packages.gz" recurse: true register: lb_pkg_index when: is_lb_master failed_when: false - name: Set offline LB repo root ansible.builtin.set_fact: offline_lb_repo_root: "{{ (lb_pkg_index.files | first).path | dirname }}" when: - is_lb_master - lb_pkg_index is defined - (lb_pkg_index.matched | default(0) | int) > 0 - name: Write offline LB apt source list (masters only, best effort) ansible.builtin.copy: dest: "{{ offline_lb_repo_list }}" mode: "0644" content: | deb [trusted=yes] file:{{ offline_lb_repo_root | default(offline_lb_repo_dir) }} ./ when: is_lb_master failed_when: false # 配置完离线源后刷新 apt cache - name: Update apt cache after configuring offline repos ansible.builtin.apt: update_cache: true cache_valid_time: 3600 # 安装常用工具(失败不致命:可能某些包不在 repo 里) - name: Install common offline tools packages ansible.builtin.apt: name: "{{ offline_tools_packages }}" state: present update_cache: false failed_when: false # ------------------------- # containerd 安装与配置 # ------------------------- - name: Ensure containerd is installed ansible.builtin.apt: name: "{{ offline_containerd_packages }}" state: present update_cache: false # 写入 containerd 配置(包含 SystemdCgroup=true 等) - name: Write containerd config.toml ansible.builtin.copy: dest: "{{ containerd_config }}" mode: "0644" content: | version = 2 root = "/var/lib/containerd" state = "/run/containerd" [grpc] address = "/run/containerd/containerd.sock" [plugins."io.containerd.grpc.v1.cri"] sandbox_image = "{{ containerd_sandbox_image }}" [plugins."io.containerd.grpc.v1.cri".containerd] snapshotter = "overlayfs" default_runtime_name = "runc" [plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc] runtime_type = "io.containerd.runc.v2" [plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc.options] SystemdCgroup = true [plugins."io.containerd.grpc.v1.cri".registry.mirrors] [plugins."io.containerd.grpc.v1.cri".registry.mirrors."docker.io"] endpoint = ["https://registry-1.docker.io"] notify: Restart containerd - name: Enable & start containerd ansible.builtin.systemd: name: containerd enabled: true state: started # 配置 crictl 默认连接 containerd socket - name: Configure crictl ansible.builtin.copy: dest: /etc/crictl.yaml mode: "0644" content: | runtime-endpoint: unix:///run/containerd/containerd.sock image-endpoint: unix:///run/containerd/containerd.sock timeout: 10 debug: false # ------------------------- # k8s keyring(可选)与 k8s 组件安装 # ------------------------- - name: Ensure /etc/apt/keyrings exists ansible.builtin.file: path: /etc/apt/keyrings state: directory mode: "0755" - name: Copy kubernetes apt keyring if exists on controller ansible.builtin.copy: src: "{{ offline_k8s_keyring_src }}" dest: "{{ offline_k8s_keyring_dest }}" mode: "0644" when: hostvars['localhost'].controller_has_k8s_keyring | default(false) - name: Install kubeadm/kubelet/kubectl and deps ansible.builtin.apt: name: "{{ offline_k8s_packages }}" state: present update_cache: false # 锁定版本,避免被 apt upgrade 意外升级 - name: Hold kubeadm/kubelet/kubectl ansible.builtin.command: "apt-mark hold kubeadm kubelet kubectl" changed_when: false failed_when: false - name: Enable kubelet ansible.builtin.systemd: name: kubelet enabled: true state: started # ------------------------- # VIP LB:haproxy + keepalived(仅两台 master) # ------------------------- - name: Install haproxy and keepalived on masters ansible.builtin.apt: name: - haproxy - keepalived state: present update_cache: false when: is_lb_master # haproxy 将 VIP:16443 转发到 两台 master 的 6443 - name: Write haproxy config for apiserver VIP ansible.builtin.copy: dest: /etc/haproxy/haproxy.cfg mode: "0644" content: | global log /dev/log local0 log /dev/log local1 notice daemon maxconn 20000 defaults log global mode tcp option tcplog timeout connect 5s timeout client 1m timeout server 1m frontend kube-apiserver bind *:{{ apiserver_vip_port }} default_backend kube-apiserver backend kube-apiserver option tcp-check balance roundrobin server {{ lb_masters[0] }} {{ hostvars[lb_masters[0]].ansible_default_ipv4.address }}:{{ apiserver_bind_port }} check server {{ lb_masters[1] }} {{ hostvars[lb_masters[1]].ansible_default_ipv4.address }}:{{ apiserver_bind_port }} check when: is_lb_master notify: Restart haproxy # 修复点:只在 master 写 keepalived 脚本,并确保目录存在 - name: Ensure /etc/keepalived exists (masters only) ansible.builtin.file: path: /etc/keepalived state: directory mode: "0755" when: is_lb_master # keepalived 健康检查脚本:haproxy 进程存在即认为健康 - name: Write keepalived health check script (masters only) ansible.builtin.copy: dest: /etc/keepalived/check_haproxy.sh mode: "0755" content: | #!/usr/bin/env bash pgrep haproxy >/dev/null 2>&1 when: is_lb_master # keepalived VRRP:两台都 BACKUP,用 priority 决定谁持有 VIP - name: Write keepalived config ansible.builtin.copy: dest: /etc/keepalived/keepalived.conf mode: "0644" content: | global_defs { router_id {{ inventory_hostname }} } vrrp_script chk_haproxy { script "/etc/keepalived/check_haproxy.sh" interval 2 fall 2 rise 2 } vrrp_instance VI_1 { state BACKUP interface {{ apiserver_vip_iface }} virtual_router_id {{ keepalived_virtual_router_id }} priority {{ 150 if inventory_hostname == lb_masters[0] else 100 }} advert_int 1 authentication { auth_type PASS auth_pass {{ keepalived_auth_pass }} } virtual_ipaddress { {{ apiserver_vip }}/24 } track_script { chk_haproxy } } when: is_lb_master notify: Restart keepalived - name: Enable & start haproxy/keepalived ansible.builtin.systemd: name: "{{ item }}" enabled: true state: started loop: - haproxy - keepalived when: is_lb_master # 确认 haproxy 已经监听 VIP 端口(本地 127.0.0.1:16443) - name: Wait haproxy port listening on masters ansible.builtin.wait_for: host: "127.0.0.1" port: "{{ apiserver_vip_port }}" timeout: 30 when: is_lb_master # ------------------------- # kubeadm init(仅 init master) # ------------------------- - name: Check if cluster already initialized ansible.builtin.stat: path: /etc/kubernetes/admin.conf register: adminconf_stat when: is_init_master # 修复点:apiVersion 使用 v1beta3(与你的 kubeadm 版本匹配) - name: Write kubeadm config ansible.builtin.copy: dest: /root/kubeadm.yaml mode: "0644" content: | apiVersion: kubeadm.k8s.io/v1beta3 kind: ClusterConfiguration kubernetesVersion: "{{ kubeadm_kubernetes_version }}" imageRepository: "{{ kubeadm_image_repository }}" controlPlaneEndpoint: "{{ apiserver_vip }}:{{ apiserver_vip_port }}" networking: podSubnet: "{{ pod_subnet }}" serviceSubnet: "{{ service_subnet }}" dnsDomain: "{{ cluster_domain }}" apiServer: certSANs: - "{{ apiserver_vip }}" - "{{ hostvars[lb_masters[0]].ansible_default_ipv4.address }}" - "{{ hostvars[lb_masters[1]].ansible_default_ipv4.address }}" - "{{ lb_masters[0] }}" - "{{ lb_masters[1] }}" - "localhost" --- apiVersion: kubeadm.k8s.io/v1beta3 kind: InitConfiguration localAPIEndpoint: advertiseAddress: "{{ ansible_default_ipv4.address }}" bindPort: {{ apiserver_bind_port }} nodeRegistration: criSocket: "{{ cri_socket }}" kubeletExtraArgs: node-ip: "{{ ansible_default_ipv4.address }}" when: is_init_master and not adminconf_stat.stat.exists - name: Run kubeadm init ansible.builtin.command: argv: - kubeadm - init - "--config=/root/kubeadm.yaml" - "--upload-certs" - "--ignore-preflight-errors=SystemVerification" - "--ignore-preflight-errors=Swap" register: kubeadm_init_out when: is_init_master and not adminconf_stat.stat.exists failed_when: kubeadm_init_out.rc != 0 - name: Re-check admin.conf after kubeadm init ansible.builtin.stat: path: /etc/kubernetes/admin.conf register: adminconf_stat_after when: is_init_master - name: Ensure /root/.kube exists on init master ansible.builtin.file: path: /root/.kube state: directory mode: "0700" when: is_init_master # 让 init master 上 root 可直接 kubectl - name: Copy admin.conf to /root/.kube/config on init master ansible.builtin.copy: remote_src: true src: /etc/kubernetes/admin.conf dest: /root/.kube/config mode: "0600" when: is_init_master and (adminconf_stat_after.stat.exists | default(false)) # 生成 worker join 命令 - name: Generate worker join command (init master) ansible.builtin.command: argv: - kubeadm - token - create - "--print-join-command" register: join_worker_cmd_raw when: is_init_master and (adminconf_stat_after.stat.exists | default(false)) # 获取 control-plane join 需要的 certificate-key - name: Upload-certs and get certificate key (init master) ansible.builtin.command: argv: - kubeadm - init - phase - upload-certs - "--upload-certs" register: upload_certs_out when: is_init_master and (adminconf_stat_after.stat.exists | default(false)) - name: Extract certificate key ansible.builtin.set_fact: cert_key: "{{ (upload_certs_out.stdout_lines | select('match','^[0-9a-f]{64}$') | list | first) | default('') }}" when: is_init_master and (adminconf_stat_after.stat.exists | default(false)) # 拼出控制面 join 命令:在 worker join 命令基础上增加 --control-plane 与 --certificate-key - name: Build control-plane join command (init master) ansible.builtin.set_fact: join_cp_cmd: "{{ join_worker_cmd_raw.stdout | trim }} --control-plane --certificate-key {{ cert_key }}" when: is_init_master and (adminconf_stat_after.stat.exists | default(false)) # 把 join 命令保存成脚本文件(便于人工排障/复用) - name: Save join commands to files (init master) ansible.builtin.copy: dest: "{{ item.path }}" mode: "0700" content: | #!/usr/bin/env bash set -e {{ item.cmd }} loop: - { path: "/root/join-worker.sh", cmd: "{{ join_worker_cmd_raw.stdout | trim }}" } - { path: "/root/join-controlplane.sh", cmd: "{{ join_cp_cmd | trim }}" } when: is_init_master and (adminconf_stat_after.stat.exists | default(false)) # 关键:把 join 命令存成 localhost 的 delegate_facts,方便其它节点通过 hostvars['localhost'] 读取 - name: Set join commands as global facts on localhost ansible.builtin.set_fact: global_join_worker: "{{ join_worker_cmd_raw.stdout | trim }}" global_join_cp: "{{ join_cp_cmd | trim }}" delegate_to: localhost delegate_facts: true run_once: true when: is_init_master and (adminconf_stat_after.stat.exists | default(false)) # ------------------------- # join(其余 master / worker) # ------------------------- - name: Check if node already joined ansible.builtin.stat: path: /etc/kubernetes/kubelet.conf register: kubeletconf_stat # 第二台 master 加入 control-plane(仅 lb master,且不是 init master) - name: Join second master as control-plane ansible.builtin.command: "{{ hostvars['localhost'].global_join_cp }}" when: - is_lb_master - not is_init_master - not kubeletconf_stat.stat.exists - hostvars['localhost'].global_join_cp is defined - (hostvars['localhost'].global_join_cp | length) > 0 # worker 加入集群(非 lb master 视为 worker) - name: Join workers ansible.builtin.command: "{{ hostvars['localhost'].global_join_worker }}" when: - (not is_lb_master) - not kubeletconf_stat.stat.exists - hostvars['localhost'].global_join_worker is defined - (hostvars['localhost'].global_join_worker | length) > 0 handlers: # containerd 配置变更后重启 - name: Restart containerd ansible.builtin.systemd: name: containerd state: restarted # haproxy 配置变更后重启 - name: Restart haproxy ansible.builtin.systemd: name: haproxy state: restarted # keepalived 配置变更后重启 - name: Restart keepalived ansible.builtin.systemd: name: keepalived state: restarted # sshd 配置变更后重启 - name: Restart ssh ansible.builtin.systemd: name: ssh state: restarted
-
-
traefik-gatway 测试yamlroot@k8s-01:~# cat traefik-gateway-nginx.yaml --- apiVersion: gateway.networking.k8s.io/v1 kind: GatewayClass metadata: name: traefik spec: controllerName: traefik.io/gateway-controller --- apiVersion: gateway.networking.k8s.io/v1 kind: Gateway metadata: name: traefik-gw namespace: default spec: gatewayClassName: traefik listeners: - name: http protocol: HTTP port: 8000 # ? 这里从 80 改成 8000,匹配 Traefik 的 entryPoints.web allowedRoutes: namespaces: from: Same --- apiVersion: apps/v1 kind: Deployment metadata: name: nginx namespace: default spec: replicas: 1 selector: matchLabels: app: nginx template: metadata: labels: app: nginx spec: containers: - name: nginx image: nginx:latest ports: - containerPort: 80 --- apiVersion: v1 kind: Service metadata: name: nginx namespace: default spec: selector: app: nginx ports: - port: 80 targetPort: 80 --- apiVersion: gateway.networking.k8s.io/v1 kind: HTTPRoute metadata: name: nginx namespace: default spec: parentRefs: - name: traefik-gw namespace: default sectionName: http # ? 明确绑定到上面 listener 名称 http(可选,但更清晰) hostnames: - "nginx.example.com" rules: - matches: - path: type: PathPrefix value: / backendRefs: - name: nginx port: 80 traefik 启用 Gateway API Providerroot@k8s-01:/woke/traefik# ls Changelog.md Chart.yaml crds EXAMPLES.md Guidelines.md LICENSE README.md templates traefik-values.yaml VALUES.md values.schema.json values.yaml root@k8s-01:/woke/traefik# cat traefik-values.yaml # 1. Dashboard / API 配置 api: dashboard: true # ⚠️ 这里是顶层的 ingressRoute,不在 api 下面 ingressRoute: dashboard: enabled: false # 关键:改成 web,让它走 80 端口(NodePort 30080) entryPoints: - web matchRule: PathPrefix(`/dashboard`) || PathPrefix(`/api`) annotations: {} labels: {} middlewares: [] tls: {} # 2. 入口点配置(保持你原来的) ports: traefik: port: 8080 expose: default: false exposedPort: 8080 protocol: TCP web: port: 8000 expose: default: true exposedPort: 80 protocol: TCP nodePort: 30080 websecure: port: 8443 hostPort: containerPort: expose: default: true exposedPort: 443 protocol: TCP nodePort: 30443 # 3. Service 配置:NodePort service: enabled: true type: NodePort single: true spec: externalTrafficPolicy: Cluster annotations: {} labels: {} # 4. RBAC rbac: enabled: true # 5. metrics(你这里开 prometheus 也没问题) metrics: prometheus: enabled: true logs: general: level: INFO access: enabled: true format: common # 6. 启用 Gateway API Provider providers: kubernetesGateway: enabled: true